MLOps auf dem Lakehouse konzipieren
Ein neuer datenzentrierter Ansatz für den Aufbau robuster MLOps-Praktiken
von Joseph Bradley, Rafi Kurlansik, Matthew Thomson und Niall Turbitt
Hier bei Databricks haben wir Tausenden von Kunden dabei geholfen, Machine Learning (ML) in die Produktion zu überführen. Shell hat über 160 aktive AI-Projekte, die Millionen von Dollar einsparen; Comcast verwaltet mit MLflow mühelos Hunderte von Machine-Learning-Modellen; und viele andere haben erfolgreiche ML-gestützte Lösungen entwickelt.
Vor der Zusammenarbeit mit uns hatten viele Kunden Schwierigkeiten, ML in die Produktion zu bringen – aus gutem Grund: Machine Learning Operations (MLOps) ist eine Herausforderung. MLOps umfasst die gemeinsame Verwaltung von Code (DevOps), Daten (DataOps) und Modellen (ModelOps) auf ihrem Weg in die Produktion. Die häufigste und schmerzhafteste Herausforderung, die wir beobachtet haben, ist die Kluft zwischen Daten und ML, die oft auf schlecht miteinander verbundene Tools und Teams aufgeteilt sind.
Um diese Herausforderung zu lösen, baut Databricks Machine Learning auf der Lakehouse-Architektur auf, um deren Hauptvorteile – Einfachheit und Offenheit – auf MLOps auszuweiten.
Unsere Plattform vereinfacht ML durch die Definition eines datenzentrierten Workflows, der Best Practices aus DevOps, DataOps und ModelOps vereint. Machine-Learning-Pipelines sind letztlich Datenpipelines, bei denen Daten durch die Hände verschiedener Personas fließen. Data Engineers erfassen und bereiten Daten vor; Data Scientists erstellen Modelle aus Daten; ML-Engineers überwachen Modellmetriken; und Business Analysts untersuchen Vorhersagen. Databricks vereinfacht produktives Machine Learning, indem es diesen Datenteams ermöglicht, zusammenzuarbeiten und diese Fülle an Daten auf einer einzigen Plattform statt in Silos zu verwalten. Beispielsweise ermöglicht Ihnen unser Feature Store, Ihre Modelle und Features gemeinsam produktiv zu nutzen: Data Scientists erstellen Modelle, die „wissen“, welche Features sie benötigen, sodass ML-Engineers Modelle mit einfacheren Prozessen bereitstellen können.
Der Databricks-Ansatz für MLOps basiert auf offenen, branchenweiten Standards. Für DevOps integrieren wir uns mit Git- und CI/CD-Tools. Für DataOps bauen wir auf Delta Lake und dem Lakehouse auf, der De-facto-Architektur für eine offene und leistungsstarke Datenverarbeitung. Für ModelOps bauen wir auf MLflow auf, dem beliebtesten Open-Source-Tool für das Modellmanagement. Diese Grundlage in offenen Formaten und APIs ermöglicht es unseren Kunden, unsere Plattform an ihre vielfältigen Anforderungen anzupassen. Beispielsweise können Kunden, die das Modellmanagement um unser MLflow-Angebot herum zentralisieren, je nach Bedarf unser integriertes Model Serving oder andere Lösungen nutzen.
Wir freuen uns, unsere MLOps-Architektur in diesem Blogbeitrag vorzustellen. Wir erörtern die Herausforderungen von gemeinsamem DevOps + DataOps + ModelOps, geben einen Überblick über unsere Lösung und beschreiben unsere Referenzarchitektur. Für tiefere Einblicke laden Sie The Big Book of MLOps herunter und besuchen Sie die MLOps-Vorträge auf dem kommenden Data+AI Summit 2022.
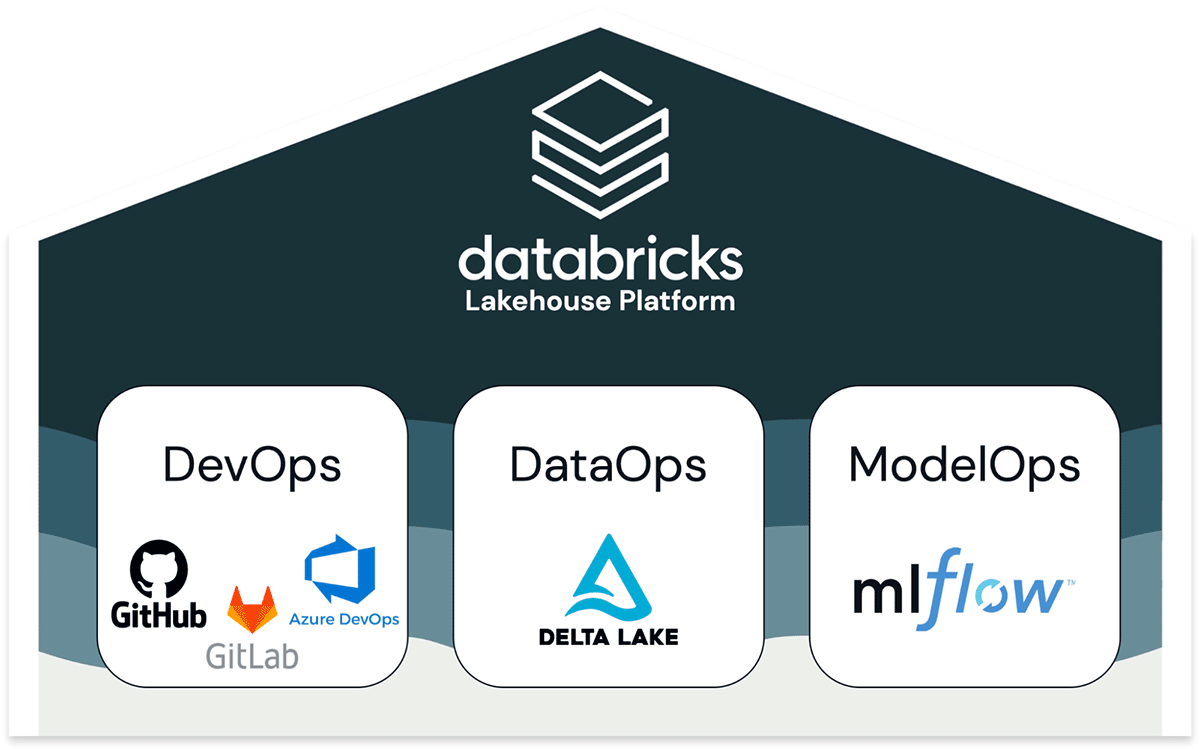
Gemeinsame Verwaltung von Code, Daten und Modellen
MLOps ist eine Reihe von Prozessen und Automatisierungen zur Verwaltung von Code, Daten und Modellen, um die beiden Ziele einer stabilen Leistung und langfristigen Effizienz in ML-Systemen zu erreichen. Kurz gesagt: MLOps = DevOps + DataOps + ModelOps.
Entwicklung, Staging und Produktion
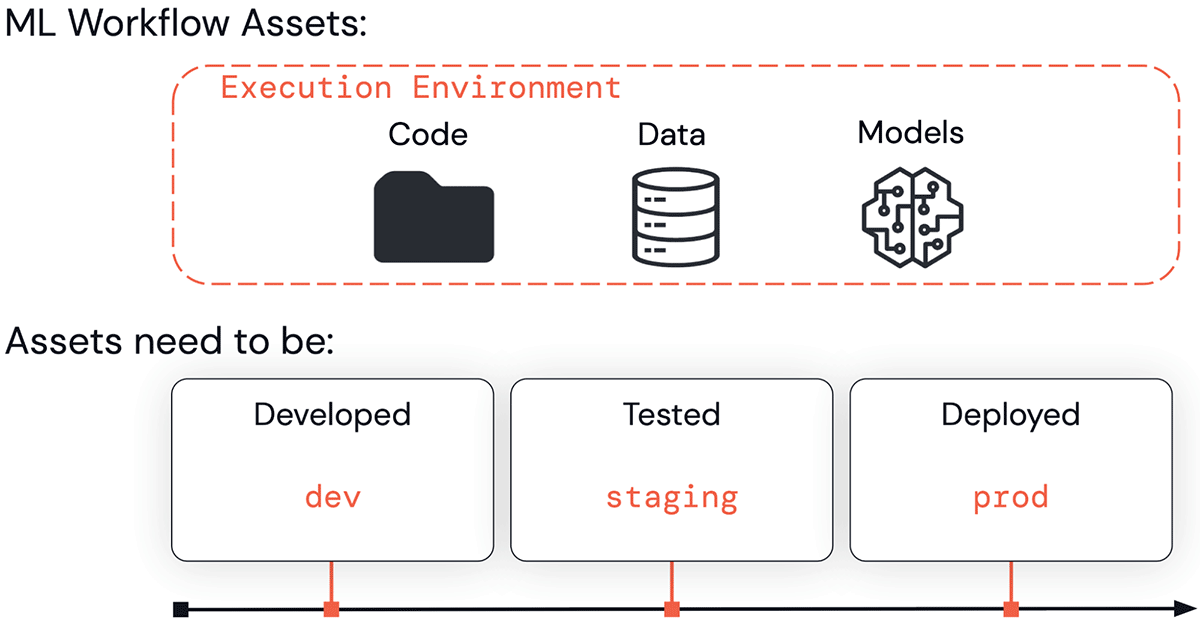
Auf ihrem Weg zu geschäfts- oder kundenorientierten Anwendungen durchlaufen ML-Assets (Code, Daten und Modelle) eine Reihe von Phasen. Sie müssen entwickelt (Phase „Entwicklung“), getestet (Phase „Staging“) und bereitgestellt (Phase „Produktion“) werden. Diese Arbeit erfolgt in Ausführungsumgebungen wie Databricks-Workspaces.
Alle oben genannten Bereiche – Ausführungsumgebungen, Code, Daten und Modelle – sind in Dev, Staging und Prod unterteilt. Diese Unterteilungen lassen sich im Hinblick auf Qualitätsgarantien und Zugriffskontrolle verstehen. Assets in der Entwicklung sind möglicherweise breiter zugänglich, weisen jedoch keine Qualitätsgarantien auf. Assets in der Produktion sind im Allgemeinen geschäftskritisch, bieten die höchsten Test- und Qualitätsgarantien, unterliegen jedoch strengen Kontrollen darüber, wer sie ändern darf.
Wichtigste Herausforderungen
Die oben genannten Anforderungen können leicht an Komplexität explodieren: Wie soll man Code, Daten und Modelle über Entwicklung, Test und Produktion hinweg, über mehrere Teams hinweg und mit Komplikationen wie Zugriffskontrollen und mehreren beteiligten Technologien verwalten? Wir haben beobachtet, dass diese Komplexität zu einigen zentralen Herausforderungen führt.
Operative Prozesse
DevOps-Konzepte lassen sich nicht direkt auf MLOps übertragen. Bei DevOps gibt es eine enge Entsprechung zwischen Ausführungsumgebungen, Code und Daten; beispielsweise führt die Produktionsumgebung nur Code auf Produktionsebene aus und erzeugt nur Daten auf Produktionsebene. ML-Modelle verkomplizieren die Sache, da Modell- und Code-Lebenszyklusphasen oft asynchron ablaufen. Möglicherweise möchten Sie eine neue Modellversion einführen, bevor Sie eine Codeänderung pushen, und umgekehrt. Betrachten Sie die folgenden Szenarien:
- Um betrügerische Transaktionen zu erkennen, entwickeln Sie eine ML-Pipeline, die ein Modell wöchentlich neu trainiert. Sie aktualisieren den Code vierteljährlich, aber jede Woche wird automatisch ein neues Modell trainiert, getestet und in die Produktion überführt. In diesem Szenario ist der Modell-Lebenszyklus schneller als der Code-Lebenszyklus.
- Um Dokumente mithilfe großer neuronaler Netze zu klassifizieren, ist das Trainieren und Bereitstellen des Modells aus Kostengründen oft ein einmaliger Prozess. Da sich nachgelagerte Systeme jedoch regelmäßig ändern, aktualisieren Sie den Code für Serving und Überwachung entsprechend. In diesem Szenario ist der Code-Lebenszyklus schneller als der Modell-Lebenszyklus.
Zusammenarbeit und Verwaltung
MLOps muss das Bedürfnis von Data Scientists nach Flexibilität und Transparenz bei der Entwicklung und Pflege von Modellen mit dem gegensätzlichen Bedürfnis von ML-Engineers nach Kontrolle über Produktionssysteme in Einklang bringen. Data Scientists müssen ihren Code auf Produktionsdaten ausführen und Protokolle, Modelle und andere Ergebnisse von Produktionssystemen einsehen können. ML-Engineers müssen den Zugriff auf Produktionssysteme einschränken, um die Stabilität zu wahren und manchmal den Datenschutz zu gewährleisten. Die Erfüllung dieser Anforderungen wird noch schwieriger, wenn die Plattform aus mehreren voneinander unabhängigen Technologien zusammengeschustert ist, die kein gemeinsames Zugriffskontrollmodell nutzen.
Integration und Anpassung
Viele Tools für ML sind nicht offen konzipiert; beispielsweise exportieren einige ML-Tools Modelle nur in Black-Box-Formaten wie JAR-Dateien. Viele Datentools sind nicht für ML ausgelegt; beispielsweise erfordern Data Warehouses den Export von Daten in ML-Tools, was die Speicherkosten erhöht und Governance-Probleme aufwirft. Wenn diese Komponententools nicht auf offenen Formaten und APIs basieren, ist es ummöglich, sie in einer einheitlichen Plattform zu integrieren.
Vereinfachung von MLOps mit dem Lakehouse
Um den Anforderungen von MLOps gerecht zu werden, hat Databricks seinen Ansatz auf der Lakehouse-Architektur aufgebaut. Lakehouses vereinen die Funktionen von Data Lakes und Data Warehouses unter einer einzigen Architektur, wobei diese Vereinfachung durch die Verwendung offener Formate und APIs ermöglicht wird, die beide Arten von Daten-Workloads unterstützen. Analog dazu bieten wir für MLOps eine einfachere Architektur, da wir MLOps um offene Datenstandards herum aufbauen.
Bevor wir uns mit den Details unseres Architekturansatzes befassen, erklären wir ihn auf einer übergeordneten Ebene und heben seine wichtigsten Vorteile hervor.
Operative Prozesse
Unser Ansatz weitet DevOps-Konzepte auf ML aus und definiert eine klare Semantik dafür, was „Überführung in die Produktion“ für Code, Daten und Modelle bedeutet. Vorhandene DevOps-Tools und CI/CD-Prozesse können wiederverwendet werden, um den Code für ML-Pipelines zu verwalten. Feature-Berechnung, Inferenz und andere Datenpipelines folgen demselben Bereitstellungsprozess wie der Modelltraining-Code, was den Betrieb vereinfacht. Ein dedizierter Dienst – die MLflow Model Registry – ermöglicht die unabhängige Aktualisierung von Code und Modellen und löst so die zentrale Herausforderung bei der Anpassung von DevOps-Methoden an ML.
Zusammenarbeit und Verwaltung
Unser Ansatz basiert auf einer einheitlichen Plattform, die Data Engineering, explorative Data Science, produktives ML und Business Analytics unterstützt – alles getragen von einer gemeinsamen Lakehouse-Datenschicht. ML-Daten werden unter derselben Lakehouse-Architektur verwaltet, die auch für andere Datenpipelines verwendet wird, was die Übergaben vereinfacht. Zugriffskontrollen für Ausführungsumgebungen, Code, Daten und Modelle sorgen dafür, dass die richtigen Teams genau den passenden Zugriff erhalten, was die Verwaltung vereinfacht.
Integration und Anpassung
Unser Ansatz basiert auf offenen Formaten und APIs: Git und zugehörige CI/CD-Tools, Delta Lake und die Lakehouse-Architektur sowie MLflow. Code, Daten und Modelle werden in Ihrem Cloud-Konto (Abonnement) in offenen Formaten gespeichert, unterstützt von Diensten mit offenen APIs. Während die unten beschriebene Referenzarchitektur vollständig in Databricks implementiert werden kann, lässt sich jedes Modul in Ihre bestehende Infrastruktur integrieren und anpassen. Beispielsweise kann das erneute Modelltraining vollständig automatisiert, teilautomatisiert oder manuell erfolgen.
Referenzarchitektur für MLOps
Wir können uns nun eine Referenzarchitektur für die Implementierung von MLOps auf der Databricks Lakehouse-Plattform ansehen. Diese Architektur – und Databricks im Allgemeinen – ist cloudunabhängig und kann auf einer oder mehreren Clouds genutzt werden. Daher handelt es sich hierbei um eine Referenzarchitektur, die an Ihre spezifischen Anforderungen angepasst werden soll. Weitere Informationen zur Architektur und zu möglichen Anpassungen finden Sie im E-Book The Big Book of MLOps.
Übersicht
Diese Architektur erklärt unseren MLOps-Prozess auf hoher Ebene. Im Folgenden beschreiben wir die wichtigsten Komponenten der Architektur und den schrittweisen Workflow zur Überführung von ML-Pipelines in die Produktion.
Komponenten
Wir definieren unseren Ansatz über die Verwaltung einiger wichtiger Assets: Ausführungsumgebungen, Code, Daten und Modelle.
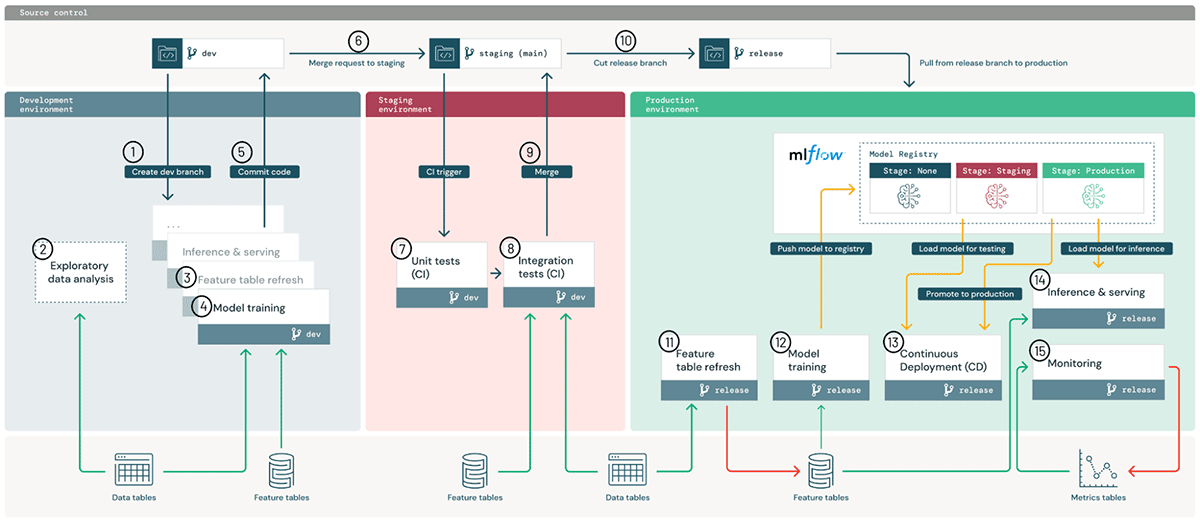
In Ausführungsumgebungen werden Modelle und Daten durch Code erstellt oder konsumiert. Umgebungen sind als Databricks-Arbeitsbereiche (AWS, Azure, GCP) für Entwicklung, Staging und Produktion definiert, wobei Zugriffskontrollen für Arbeitsbereiche verwendet werden, um die Aufgabentrennung durchzusetzen.
Im Architekturdiagramm stellen die blauen, roten und grünen Bereiche die drei Umgebungen dar.
Innerhalb von Umgebungen wird jede ML-Pipeline (kleine Kästchen im Diagramm) auf Recheninstanzen ausgeführt, die von unserem Clusters-Dienst verwaltet werden (AWS, Azure, GCP). Diese Schritte können manuell ausgeführt oder über Workflows und Jobs automatisiert werden (AWS, Azure, GCP). Jeder Schritt sollte standardmäßig eine Databricks Runtime für ML mit vorinstallierten Bibliotheken verwenden (AWS, Azure, GCP), kann aber auch benutzerdefinierte Bibliotheken nutzen (AWS, Azure, GCP).
Code zur Definition von ML-Pipelines wird zur Versionskontrolle in Git gespeichert. ML-Pipelines können Featurisierung, Modelltraining und -tuning, Inferenz sowie Überwachung umfassen. Auf hoher Ebene bedeutet „ML in die Produktion überführen“, Code von Entwicklungs-Branches über den Staging-Branch (normalerweise `main`) in Release-Branches für die produktive Nutzung zu überführen. Diese Abstimmung mit DevOps ermöglicht es Benutzern, vorhandene CI/CD-Tools zu integrieren. Im obigen Architekturdiagramm ist dieser Prozess der Code-Überführung oben dargestellt.
Bei der Entwicklung von ML-Pipelines können Data Scientists mit Notebooks beginnen und bei Bedarf zu modularisiertem Code übergehen, indem sie in Databricks oder in IDEs arbeiten. Databricks Repos lassen sich in Ihren Git-Anbieter integrieren, um Notebooks und Quellcode mit Databricks-Arbeitsbereichen zu synchronisieren (AWS, Azure, GCP). Mit den Entwicklertools von Databricks können Sie Verbindungen von IDEs und Ihren bestehenden CI/CD-Systemen herstellen (AWS, Azure, GCP).
Daten werden in einer Lakehouse-Architektur gespeichert, und zwar vollständig in Ihrem Cloud-Konto. Pipelines für Featurisierung, Inferenz und Überwachung können alle als Datenpipelines behandelt werden. Beispielsweise sollte die Modellüberwachung der Medaillon-Architektur der schrittweisen Datenbereinigung von rohen Abfrageereignissen bis hin zu aggregierten Tabellen für Dashboards folgen. Im obigen Architekturdiagramm werden Daten unten als allgemeine „Lakehouse“-Daten dargestellt, wobei die Aufteilung in Entwicklungs-, Staging- und Produktionsdaten ausgeblendet wird.
Standardmäßig sollten sowohl Rohdaten als auch Feature-Tabellen als Delta-Tabellen gespeichert werden, um Leistungs- und Konsistenzgarantien zu gewährleisten. Delta Lake bietet eine offene, effiziente Speicherschicht für strukturierte und unstrukturierte Daten mit einer optimierten Delta Engine in Databricks (AWS, Azure, GCP). Feature Store-Tabellen sind einfach Delta-Tabellen mit zusätzlichen Metadaten wie der Lineage (AWS, Azure, GCP). Unbearbeitete Dateien und Tabellen unterliegen einer Zugriffskontrolle, die je nach Bedarf gewährt oder eingeschränkt werden kann.
Modelle werden von MLflow verwaltet, was eine einheitliche Verwaltung von Modellen aus jeder ML-Bibliothek und für jeden Bereitstellungsmodus ermöglicht – sowohl innerhalb als auch außerhalb von Databricks. Databricks bietet eine verwaltete Version von MLflow mit Zugriffskontrollen, Skalierbarkeit auf Millionen von Modellen und einer Obermenge der Open-Source-MLflow-APIs.
In der Entwicklung verfolgt der MLflow Tracking-Server Prototypmodelle zusammen mit Code-Snapshots, Parametern, Metriken und anderen Metadaten (AWS, Azure, GCP). In der Produktion speichert derselbe Prozess einen Datensatz zur Reproduzierbarkeit und Governance.
Für Continuous Deployment (CD) verfolgt die MLflow Model Registry den Status der Modellbereitstellung und lässt sich über Webhooks (AWS, Azure, GCP) und über APIs (AWS, Azure, GCP) in CD-Systeme integrieren. Der Model Registry-Service verfolgt Modelllebenszyklen unabhängig von Codelebenszyklen. Diese lose Kopplung von Modellen und Code bietet die Flexibilität, Produktionsmodelle ohne Codeänderungen zu aktualisieren und umgekehrt. Beispielsweise kann eine automatisierte Pipeline für erneutes Training ein aktualisiertes Modell (ein „Development“-Modell) trainieren, es testen („Staging“-Modell) und bereitstellen („Production“-Modell) – und das alles innerhalb der Produktionsumgebung.
Die folgende Tabelle fasst die Semantik von „Development“, „Staging“ und „Production“ für Code, Daten und Modelle zusammen.
| Asset | Semantik von Dev/Staging/Prod | Verwaltung | Beziehung zu Ausführungsumgebungen |
|---|---|---|---|
| Code | Dev: Ungetestete Pipelines. Staging: Testen von Pipelines. Prod: Bereitstellungsbereite Pipelines. |
Der Code der ML-Pipeline wird in Git gespeichert, aufgeteilt in Dev-, Staging- und Release-Branches. | Die Prod-Umgebung sollte nur Code auf Prod-Ebene ausführen. Die Dev-Umgebung kann Code jeder Ebene ausführen. |
| Daten | Dev: „Dev“-Daten sind Daten, die in der Dev-Umgebung erzeugt werden.
(ebenso für Staging, Prod) |
Die Daten befinden sich im Lakehouse und können bei Bedarf über Tabellenzugriffskontrollen oder Cloud-Speicherberechtigungen umgebungsübergreifend freigegeben werden. | Prod-Daten können aus den Dev- oder Staging-Umgebungen lesbar sein oder eingeschränkt werden, um Governance-Anforderungen zu erfüllen. |
| Modelle | Dev: Neues Modell. Staging: Testen im Vergleich zu aktuellen Prod-Modellen. Prod: Bereitstellungsbereites Modell.
|
Modelle werden in der MLflow Model Registry gespeichert, die Zugriffskontrollen bereitstellt. | Modelle können ihren Lebenszyklus von Dev->Staging->Prod innerhalb jeder Umgebung durchlaufen. |
Workflow
Nachdem die Hauptkomponenten der Architektur oben erläutert wurden, können wir nun den Workflow für die Überführung von ML-Pipelines aus der Entwicklung in die Produktion durchgehen.
Development-Umgebung: Data Scientists arbeiten hauptsächlich in der Development-Umgebung und erstellen Code für ML-Pipelines, was die Feature-Berechnung, das Modelltraining, die Inferenz, das Monitoring und mehr umfassen kann.
- Dev-Branch erstellen: Neue oder aktualisierte Pipelines werden auf einem Development-Branch des Git-Projekts als Prototyp erstellt und über Repos mit dem Databricks-Workspace synchronisiert.
- Exploratorische Datenanalyse (EDA): Data Scientists untersuchen und analysieren Daten in einem interaktiven, iterativen Prozess mithilfe von Notebooks, Visualisierungen und Databricks SQL.
- Feature-Tabelle aktualisieren: Die Featurisierungslogik ist als Pipeline gekapselt, die aus dem Feature Store und anderen Lakehouse-Tabellen lesen und in den Feature Store schreiben kann. Feature-Pipelines können separat von anderen ML-Pipelines verwaltet werden, insbesondere wenn sie von verschiedenen Teams betreut werden.
- Modelltraining und andere Pipelines: Data Scientists entwickeln diese Pipelines entweder auf schreibgeschützten Produktionsdaten oder auf geschwärzten oder synthetischen Daten. In dieser Referenzarchitektur werden die Pipelines (nicht die Modelle) in Richtung Produktion überführt; siehe das vollständige Whitepaper für eine Diskussion über die Überführung von Modellen bei Bedarf.
- Code committen: Neue oder aktualisierte ML-Pipelines werden in die Versionsverwaltung übertragen. Aktualisierungen können eine einzelne ML-Pipeline oder viele gleichzeitig betreffen.
Staging-Umgebung: ML-Engineers sind für die Staging-Umgebung verantwortlich, in der ML-Pipelines getestet werden.
- Merge (Pull) Request: Ein Merge Request für den Staging-Branch (normalerweise der „main“-Branch) löst einen Continuous Integration (CI)-Prozess aus.
- Unit-Tests (CI): Der CI-Prozess führt zuerst Unit-Tests aus, die nicht mit Daten oder anderen Diensten interagieren.
- Integrationstests (CI): Der CI-Prozess führt anschließend längere Integrationstests aus, die ML-Pipelines gemeinsam testen. Integrationstests, die Modelle trainieren, können aus Geschwindigkeitsgründen kleine Datenmengen oder wenige Iterationen verwenden.
- Mergen: Wenn die Tests erfolgreich sind, kann der Code mit dem Staging-Branch zusammengeführt werden.
- Release-Branch erstellen: Wenn der Code bereit ist, kann er in der Produktion bereitgestellt werden, indem ein Code-Release erstellt und das CI/CD-System zur Aktualisierung der Produktionsjobs ausgelöst wird.
Production-Umgebung: ML-Engineers sind für die Production-Umgebung verantwortlich, in der ML-Pipelines bereitgestellt werden.
- Feature-Tabelle aktualisieren: Diese Pipeline erfasst neue Produktionsdaten und aktualisiert die Feature-Store-Tabellen der Produktion. Es kann sich um einen Batch- oder Streaming-Job handeln, der geplant, ausgelöst oder kontinuierlich ausgeführt wird.
- Modelltraining: Modelle werden auf den vollständigen Produktionsdaten trainiert und an die MLflow Model Registry übergeben. Das Training kann durch Codeänderungen oder durch automatisierte Jobs für erneutes Training ausgelöst werden.
- Continuous Deployment (CD): Ein CD-Prozess übernimmt neue Modelle (in Model Registry „stage=None“), testet sie (Übergang zu „stage=Staging“) und stellt sie bei Erfolg bereit (Überführung zu „stage=Production“). CD kann mithilfe von Model Registry-Webhooks und/oder Ihrem eigenen CD-System implementiert werden.
- Inferenz und Serving: Das Produktionsmodell der Model Registry kann in mehreren Modi bereitgestellt werden: Batch- und Streaming-Jobs für Anwendungsfälle mit hohem Durchsatz und Online-Serving für Anwendungsfälle mit geringer Latenz (REST-API).
- Monitoring: Für jeden Bereitstellungsmodus werden die Eingabeabfragen und Vorhersagen des Modells in Delta-Tabellen protokolliert. Von dort aus können Jobs Daten- und Modelldrift überwachen, und Databricks SQL-Dashboards können den Status anzeigen und Warnungen senden. In der Development-Umgebung kann Data Scientists Zugriff auf Protokolle und Metriken gewährt werden, um Produktionsprobleme zu untersuchen.
- Erneutes Training: Modelle können über einen einfachen Zeitplan auf den neuesten Daten neu trainiert werden, oder Monitoring-Jobs können ein erneutes Training auslösen.
Implementieren Sie Ihre MLOps-Architektur
Wir hoffen, dieser Blog hat Ihnen einen Eindruck davon vermittelt, wie eine datenzentrierte MLOps-Architektur basierend auf dem Lakehouse-Paradigma die gemeinsame Verwaltung von Code, Daten und Modellen vereinfacht. Dieser Blog ist notwendigerweise kurz gehalten und lässt viele Details aus. Um mit der Implementierung oder Verbesserung Ihrer MLOps-Architektur zu beginnen, empfehlen wir Folgendes:
- Lesen Sie das vollständige eBook, das weitere Details zu den Workflow-Schritten sowie eine Diskussion von Optionen und Anpassungen bietet. Laden Sie es hier herunter.
- Besuchen Sie die Vorträge zu MLOps auf dem Data+AI Summit 2022 vom 27. bis 30. Juni. Zu den Highlights gehören:
- High-Level-Vorträge
- Day 2 Opening Keynotes: Mitgründer und Produktmanager teilen die neueste Vision und Roadmaps für Open-Source- und Databricks-Projekte rund um DS und ML.
- ML on the Lakehouse: Bringing Data and ML Together to Accelerate AI Use Cases: Databricks-Produktmanager und ein Kunde geben einen Überblick über Machine Learning in einer Lakehouse-Architektur.
- Deep Dives von Databricks zu MLOps
- MLOps on Databricks: A How-To Guide: Die Autoren dieses Blogbeitrags werden die Details des eBooks durchgehen und den MLOps-Prozess in Databricks demonstrieren.
- MLflow Pipelines: Beschleunigung von MLOps von der Entwicklung bis zur Produktion: Databricks-Engineers bieten einen Deep Dive zu dieser neuesten Innovation in MLflow.
- ML in der Produktion mit Databricks Feature Store ermöglichen: Databricks-Engineers bieten einen Deep Dive zum Feature Store.
- Kunden berichten über ihre ML-Plattformen
- High-Level-Vorträge
- Sprechen Sie mit Ihrem Databricks-Account-Team, das Sie bei der Besprechung Ihrer Anforderungen unterstützt, Ihnen bei der Anpassung dieser Referenzarchitektur an Ihre Projekte hilft und bei Bedarf weitere Ressourcen für Schulung und Implementierung bereitstellt.
Für weitere Hintergrundinformationen zu MLOps empfehlen wir:
- Bedarf an datenzentrierten ML-Plattformen → Dieser Beitrag erklärt MLOps und die Notwendigkeit der Datenzentrierung im Detail und führt durch ein konkretes Beispiel eines Datenteams, das eine neue ML-gestützte Anwendung entwickelt.
- Drei Prinzipien für die Auswahl von Machine-Learning-Plattformen → Dieser Beitrag ist eine Ebene höher angesiedelt als der aktuelle Beitrag. Er befasst sich mit der Technologieauswahl für ML-Plattformen, gibt allgemeine Richtlinien vor und führt entsprechende Kundenberichte an.
- Der umfassende Leitfaden für Feature Stores → Feature Stores sind ein ganz eigenes Thema für sich. Dieser Leitfaden bietet einen tiefen Einblick.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.