Rethinking Data Streaming: Why It's Viable for More Use Cases than You Might Expect
by Matt Jones
In today's data-driven world, organizations face the challenge of effectively ingesting and processing data at an unprecedented scale. With the amount and variety of business-critical data constantly being generated, the architectural possibilities are nearly infinite - and that can be overwhelming. The good news? This also means there is always potential to optimize your data architecture further - for throughput, latency, cost, and operational efficiency.
Many data professionals associate terms like "data streaming" and "streaming architecture" with hyper-low-latency data pipelines that seem complex, costly, and impractical for most workloads. However, teams that employ a streaming data architecture on the Databricks Data Intelligence Platform frequently benefit from improved throughput, less operational overhead, and drastically reduced costs. Some of these users operate at real-time, subsecond latency; while others run jobs as infrequently as once per day. Some construct their own Spark Structured Streaming pipelines; others use DLT pipelines, a declarative approach built on Spark Structured Streaming where all the infrastructure and operational overhead is automatically managed (many teams use a mix of both).
No matter what your team's requirements and SLAs are, we're willing to bet a lakehouse streaming architecture for centralized data processing, data warehousing, and AI will deliver more value than other approaches. In this blog we'll discuss common architectural challenges, how Spark Structured Streaming is specifically designed to address them, and why the Databricks Data Intelligence Platform, built on Lakehouse architecture, offers the best context for operationalizing a streaming architecture that saves time and money for data teams today.
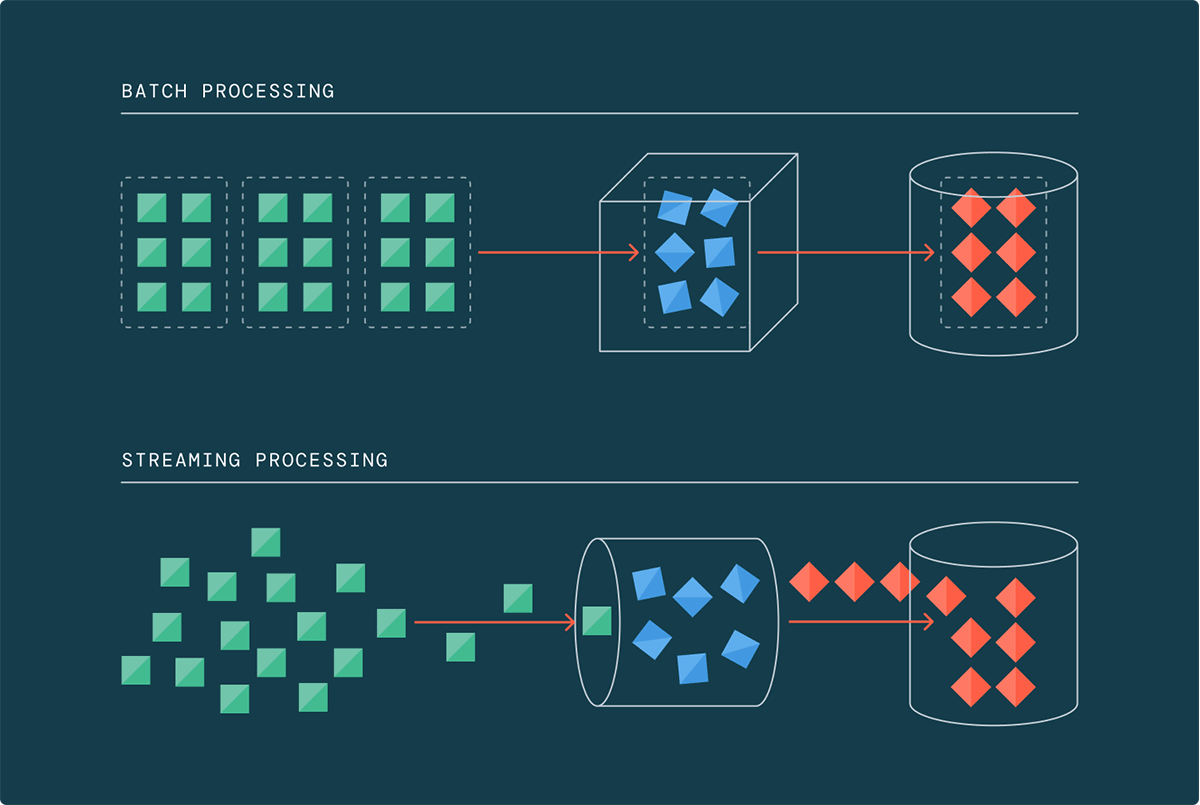
Transitioning from Batch to Streaming
Traditionally, data processing was done in batches, where data was collected and processed at scheduled intervals. However, this approach is no longer adequate in the age of big data, where data volumes, velocity, and variety continue to grow exponentially. With 90% of the world's data generated in the last two years alone, the traditional batch processing framework struggles to keep pace.
This is where data streaming comes into play. Streaming architectures enable data teams to process data incrementally as it arrives, eliminating the need to wait for a large batch of data to accumulate. When operating at terabyte and petabyte scales, allowing data to accumulate becomes impractical and costly. Streaming has offered a vision and a promise for years that today it is finally able to deliver on.
Rethinking Common Use Cases: Streaming Is the New Normal
The world is increasingly reliant on real-time data, and data freshness can be a significant competitive advantage. But, the fresher you want your data, the more expensive it typically becomes. We talk to a lot of customers who express a desire for their pipelines to be "as real-time as possible" - but when we dig into their specific use case, it turns out they would be plenty happy to reduce their pipeline runs from 6 hours to under 15 minutes. Other customers really do need latency that you can only measure in seconds or milliseconds.

Rather than categorizing use cases as batch or streaming, it's time to view every workload through the lens of streaming architecture. Think of it as a single slider that can be adjusted to optimize for performance at one end, or for cost efficiency at the other. In essence, streaming allows you to set the slider to the optimal position for each workload, from ultra-low latency to minutes or even hours.
Our very own Dillon Bostwick said it better than I ever could: "We must get out of the mindset of reserving streaming for complex "real-time" use cases. Instead, we should use it for "Right-time processing."

Spark Structured Streaming offers a unified framework that lets you adjust this slider, providing a massive competitive advantage for businesses and data engineers. Data freshness can adapt to meet business requirements without the need for significant infrastructure changes.
Contrary to many common definitions, data streaming doesn’t always mean continuous data processing. At its core, streaming is about processing data in small, incremental pieces as it arrives — not necessarily in real time. You can choose when to permit incremental processing - always on or triggered at specific intervals. While streaming makes sense for ultra-fresh data, it's also applicable to data traditionally considered as batch.
Future-Proofing With Spark-Based Streaming on Databricks
Consider future-proofing your data architecture. Streaming architectures offer flexibility to adjust latency, cost, or throughput requirements as they evolve. Here are some benefits of fully streaming architectures and why Spark Structured Streaming on Databricks is designed for them:
- Scalability and throughput: Streaming architectures inherently scale and handle varying data volumes without major infrastructure changes. Spark Structured Streaming excels in scalability and performance, especially on top of Databricks leveraging Photon.
For many use cases, as long as teams are hitting an acceptable latency SLA, the ability to handle high throughput is even more important. Spark Structured Streaming can hit subsecond latency at millions of events per second, which is why enterprises like AT&T and Akamai that are regularly handling petabytes of data trust Databricks for their streaming workloads."Databricks has helped Comcast scale to processing billions of transactions and terabytes of [streaming] data every day." —Jan Neumann, VP Machine Learning, Comcast
"Delta Live Tables has helped our teams save time and effort in managing data at the multi-trillion-record scale and continuously improving our AI engineering capability." —Dan Jeavons, GM Data Science, Shell
"We didn't have to do anything to get DLT to scale. We give the system more data, and it copes. Out of the box, it's given us the confidence that it will handle whatever we throw at it." —Dr. Chris Inkpen, Global Solutions Architect, Honeywell
- Simplicity: When you're running a batch job that performs incremental updates, you generally have to deal with figuring out what data is new, what you should process, and what you should not. Structured Streaming already does all this for you, handling bookkeeping, fault tolerance, and stateful operations, providing an "exactly once" guarantee without manual oversight. Setting up and running streaming jobs, particularly through Delta Live Tables, is incredibly straightforward.
"With Databricks, the actual streaming mechanics have been abstracted away… this has made ramping up on streaming so much simpler." —Pablo Beltran, Software Engineer, Statsig
"I love Delta Live Tables because it goes beyond the capabilities of Auto Loader to make it even easier to read files. My jaw dropped when we were able to set up a streaming pipeline in 45 minutes… we just pointed the solution at a bucket of data and were up and running." —Kahveh Saramout, Senior Data Engineer, Labelbox
"DLT is the easiest way to create a consumption data set; it does everything for you. We're a smaller team, and DLT saves us so much time." —Ivo Van de Grift, Data Team Tech Lead, Etos (an Ahold-Delhaize brand)
- Data Freshness for Real-Time Use Cases: Streaming architectures ensure up-to-date data, a crucial advantage for real-time decision-making and anomaly detection. For use cases where low latency is key, Spark Structured Streaming (and by extension, DLT pipelines) can deliver inherent subsecond latency at scale.
Even use cases that don't require ultra-low latency can benefit from reduced latency variability. Streaming architectures provide more consistent processing times, making it easier to meet service-level agreements and ensure predictable performance. Spark Structured Streaming on Databricks allows you to configure the exact latency/throughput/cost tradeoff that's right for your use case."Our business requirements demanded increased freshness of data, which only a streaming architecture could provide." —Parveen Jindal, Software Engineering Director, Vizio
"We use Databricks for high-speed data in motion. It really helps us transform the speed at which we can respond to our patients' needs either in-store or online." —Sashi Venkatesan, Product Engineering Director, Walgreens
"We've seen major improvements in the speed we have data available for analysis. We have a number of jobs that used to take 6 hours and now take only 6 seconds." —Alessio Basso, Chief Architect, HSBC
- Cost Efficiency: Nearly every customer we talk to who migrates to a streaming architecture with Spark Structured Streaming or DLT on Databricks realizes instant and significant cost savings. Adopting streaming architectures can lead to significant cost savings, especially for variable workloads. With Spark Structured Streaming, you only consume resources when processing data, eliminating the need for dedicated clusters for batch processing.
Customers using DLT pipelines realize even more cost savings from increased development velocity and drastically reduced time spent managing operational minutiae like deployment infrastructure, dependency mapping, version control, checkpointing and retries, backfill handling, governance, and so on."As more real-time and high-volume data feeds were activated for consumption [on Databricks], ETL/ELT costs increased at a proportionally lower and linear rate compared to the ETL/ELT costs of the legacy Multi Cloud Data Warehouse." —Sai Ravuru, Senior Manager of Data Science & Analytics, JetBlue
"The best part is that we're able to do all of this more cost-efficiently. For the same cost as our previous multi-cloud data warehouse, we can work faster, more collaboratively, more flexibly, with more data sources, and at scale." —Alexander Booth, Assistant Director of R&D, Texas Rangers
"Our focus to optimize price/performance was met head-on by Databricks… infrastructure costs are 34% lower than before, and there's been a 24% cost reduction in running our ETL pipelines as well. More importantly, our rate of experimentation has improved tremendously." —Mohit Saxena, Co-founder and Group CTO, InMobi
- Unified Governance Across Real-Time and Historical Data: Streaming architectures centralized on the Databricks Data Intelligence Platform offer the most practical path to unified governance across real-time and historical data. Only Databricks includes Unity Catalog, the industry's first unified governance solution for data and AI. Governance through Unity Catalog accelerates data and AI initiatives while ensuring regulatory compliance in a simplified manner, ensuring streaming pipelines and real-time applications sit within the broader context of a singularly governed data platform.
"Doing everything from ETL and engineering to analytics and ML under the same umbrella removes barriers and makes it easy for everyone to work with the data and each other." —Sergey Blanket, Head of Business Intelligence, Grammarly
"Before we had support for Unity Catalog, we had to use a separate process and pipeline to stream data into S3 storage and a different process to create a data table out of it. With Unity Catalog integration, we can streamline, create and manage tables from the DLT pipeline directly." —Yue Zhang, Staff Software Engineer, Block
"Databricks has helped Columbia's EIM team accelerate ETL and data preparation, achieving a 70% reduction in ETL pipeline creation time while reducing the amount of time to process ETL workloads from 4 hours to only 5 minutes… More business units are using it across the enterprise in a self-service manner that was not possible before. I can't say enough about the positive impact that Databricks has had on Columbia." —Lara Minor, Senior Enterprise Data Manager, Columbia Sportswear
Streaming architectures prepare your data infrastructure for evolving needs as data generation continues to accelerate. By preparing for real-time data processing now, you'll be better equipped to handle increasing data volumes and evolving business needs. In other words - you can easily tweak that slider if your latency SLAs evolve, rather than having to rearchitect.
Getting Started with Databricks for Streaming Architectures
There are several reasons that over 2,000 customers are running more than 10 million weekly streaming jobs on Databricks. Customers trust Databricks for building streaming architectures because:
- While many multi-cloud data warehouses aren't built for streaming, Databricks supports streaming analytics, ML, and real-time applications natively — all on a unified platform.
- Compared to Flink, Databricks offers a much simpler experience and gives teams the flexibility to adjust the cost/latency tradeoff at any time, based on their specific needs.
- Public cloud-native solutions often require stitching together multiple services — with Databricks, you get a single, unified platform for batch and streaming workloads.
- Databricks gives teams the freedom to choose how they want to build: whether they prefer full control with Spark Structured Streaming or want to simplify operations using DLT pipelines. Many customers use both approaches across different pipelines, depending on their goals.
Here are a few ways to start exploring streaming architectures on Databricks:
- Visit the Streaming and Delta Live Tables product pages
- Explore more customer stories here
- Read about how we performed ETL on one billion records for $1
- Browse our catalog of streaming and DLT demos here. Some great places to start include the DLT product tour, CDC pipeline demo, and advanced streaming demo.
- Review technical documentation getting started with Streaming on Databricks and Delta Live Tables
Takeaways
Streaming architectures have several benefits over traditional batch processing, and are only becoming more necessary. Spark Structured Streaming allows you to implement a future-proof streaming architecture now and easily tune for cost vs. latency. Databricks is the best place to run Spark workloads.
If your business requires 24/7 streams and real-time analytics, ML, or operational apps, then run your clusters 24/7 with Structured Streaming in continuous mode. If it doesn't, then use Structured Streaming's incremental batch processing with Trigger = AvailableNow. (See our documentation specifically around optimizing costs by balancing always-on and triggered streaming). Either way, consider DLT pipelines for automating most of the operational overhead.
In short - if you are processing a lot of data, you probably need to implement a streaming architecture. From once-a-day to once-a-second and below, Databricks makes it easy and saves you money.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.