Lakehouse Orchestration with Databricks Workflows
by Ori Zohar, Richard Tomlinson, Bilal Aslam, Erika Ehrli and Roland Fäustlin
Organizations across industries are adopting the lakehouse architecture and using a unified platform for all their data, analytics and AI workloads. When moving their workloads into production, organizations are finding that the way they orchestrate their workloads is critical for the value they are able to extract from their data and AI solutions. Orchestration done right can improve data teams' productivity and accelerate innovation, it can provide better insights and observability and finally, it can improve pipeline reliability and resource utilization.
All of these potential benefits of orchestration are within reach for customers who choose to leverage the Databricks Lakehouse Platform but only if they choose an orchestration tool that is well-integrated with the Lakehouse. Databricks Workflows is the unified orchestration solution for the Lakehouse and is the best choice when compared to the alternatives.
Choosing the Right Orchestration Tool
Data engineering teams have multiple options to choose from when considering how to implement workload orchestration. Some data engineers have the impulse to build their own orchestrator in-house while others prefer external open source tools or choose the services their cloud provider offers as a default. Although all of these options are valid, when it comes to orchestrating workloads on their Lakehouse platform, some clear drawbacks come to mind:
Increased complexity for end-users - With some orchestration tools, defining a workflow can be complex, requiring specialized knowledge and a deep familiarity with the tool of choice. Consider Apache Airflow which has a steep learning curve, especially for users who are unfamiliar with workflow authoring and management. The programmatic creation of DAGs (Directed Acyclic Graphs), operators, tasks, and connections can be initially overwhelming, requiring significant time and effort to become proficient in using Airflow effectively. As a result, it becomes difficult for data analysts and data scientists to define and manage their own orchestrated workflows who then tend to rely on data engineering teams specializing in orchestration. This dependency slows down innovation and puts a higher burden on data engineers. In addition, external tools take users out of their Databricks environment which slows down day-to-day work with unnecessary "context switching" and added friction.
Limited monitoring and observability capabilities - A key factor in choosing an orchestration tool is the level of observability it provides you as a user. Monitoring pipelines is critical, especially in production environments where fast failure identification is critical. Orchestration tools that operate outside the data platform where your workloads run usually means they can only provide a shallow level of observability. You may know a workflow has failed but not have enough information on what specific task caused the failure or why the failure occurred. While many orchestrators provide basic monitoring and logging capabilities, troubleshooting and debugging can be challenging for complex workflows. Tracking dependencies, identifying data quality issues, and managing errors can require additional effort and customizations. This makes troubleshooting hard and prevents teams from fast recovery when issues arise.
Unreliable and inefficient production workflows - Managing an in-house built orchestration solution, or an external tool deployed on dedicated cloud infrastructure requires costly maintenance on top of infrastructure fees and are prone to suffer from failures and downtime. Airflow for example, requires its own distributed infrastructure to handle large-scale workflows effectively. Setting up and managing additional clusters adds complexity and cost, especially for organizations without prior expert knowledge. This is especially painful in production scenarios where pipeline failures have real repercussions for data consumers and/or customers. In addition, using a tool that is not well integrated with your data platform means it is unable to leverage advanced capabilities for efficient resource allocation and scheduling that directly affect cost and performance.
Meet Databricks Workflows, the Lakehouse Orchestrator
When approaching the question of how to best orchestrate workloads on the Databricks Lakehouse Platform, Databricks Workflows is the clear answer. Fully integrated with the lakehouse, Databricks Workflows is a fully managed orchestration service that allows you to orchestrate any workload - including ETL pipelines, SQL analytics and BI, through machine learning training, model deployment and inference. When it comes to the considerations mentioned above, these are well satisfied with Databricks Workflows:
Simple authoring for all your data practitioners - Defining a new workflow can be done in the Databricks UI with just a few clicks or can be achieved via your IDE. Whether you are a data engineer, a data analyst or a data scientist, you can easily author and manage the custom workflow you need without learning new tools or depending on other specialized teams.
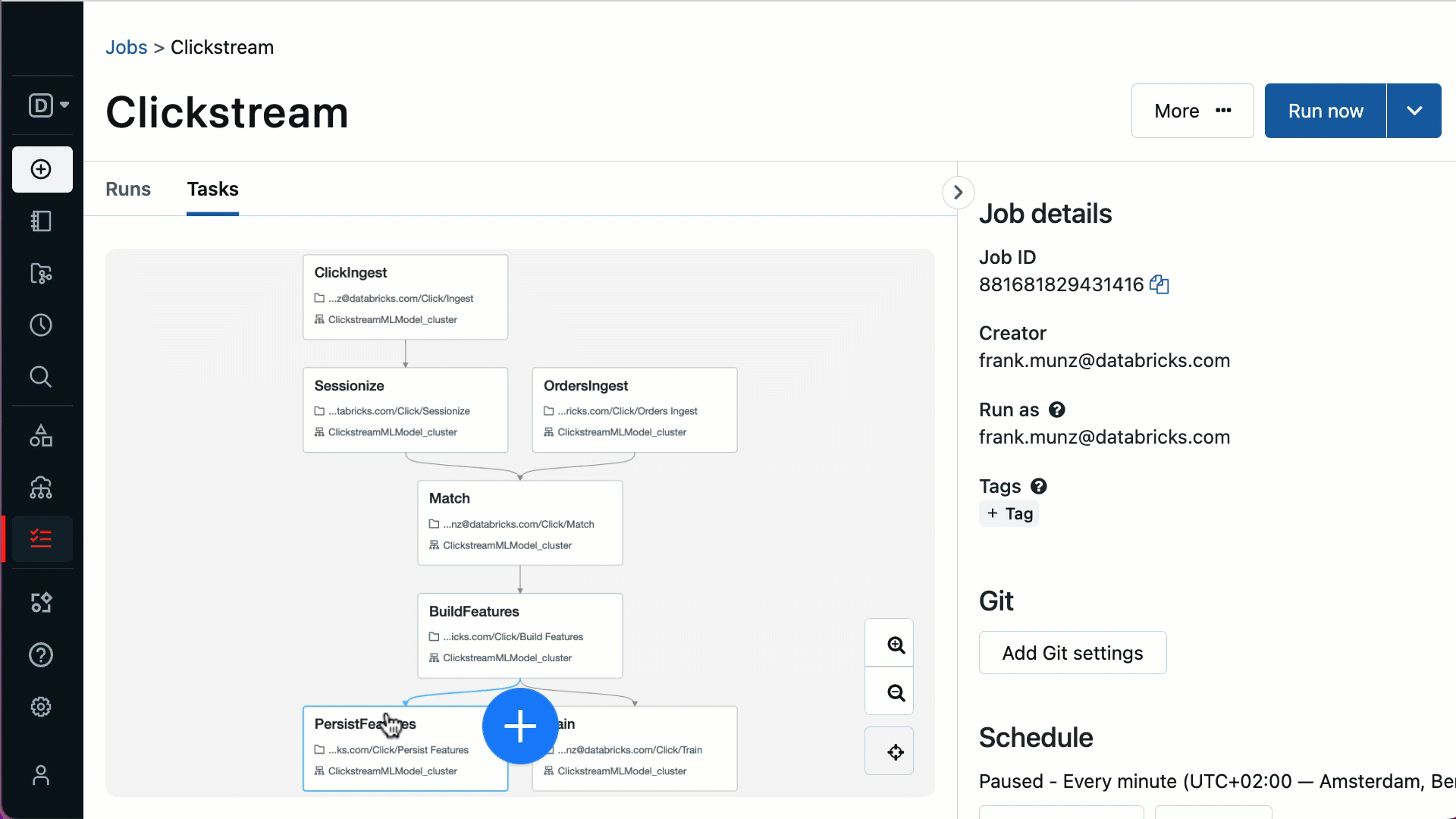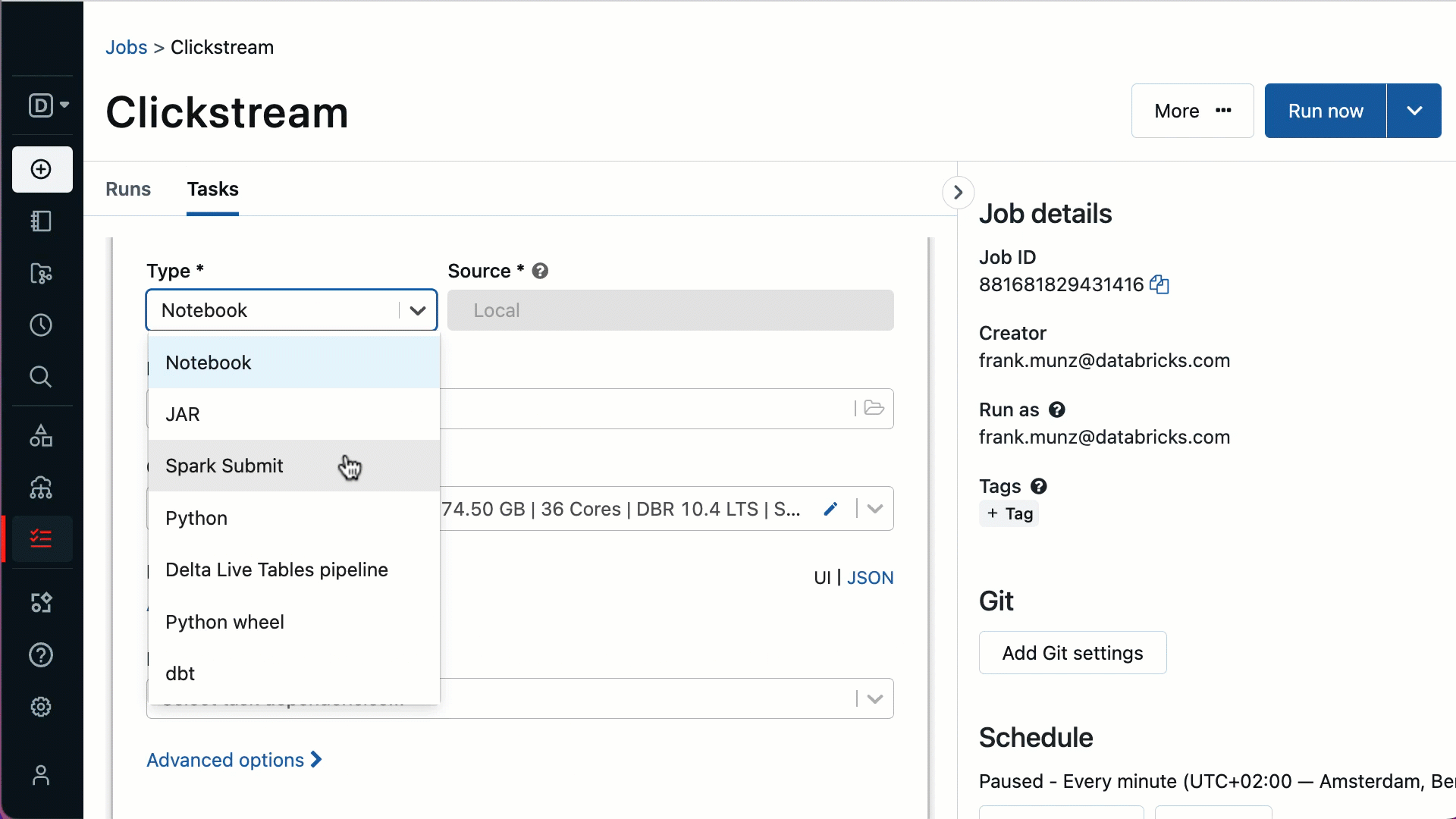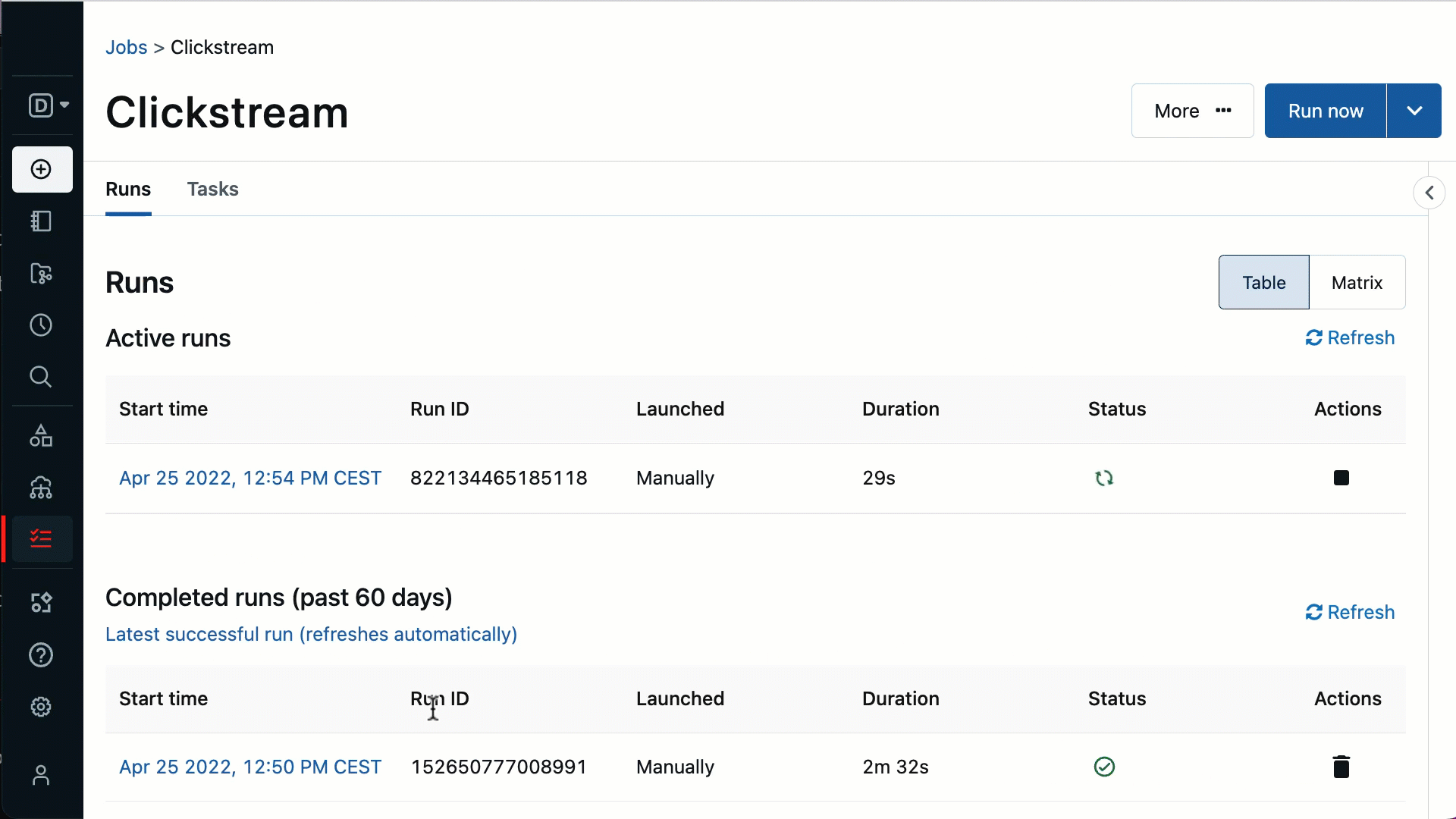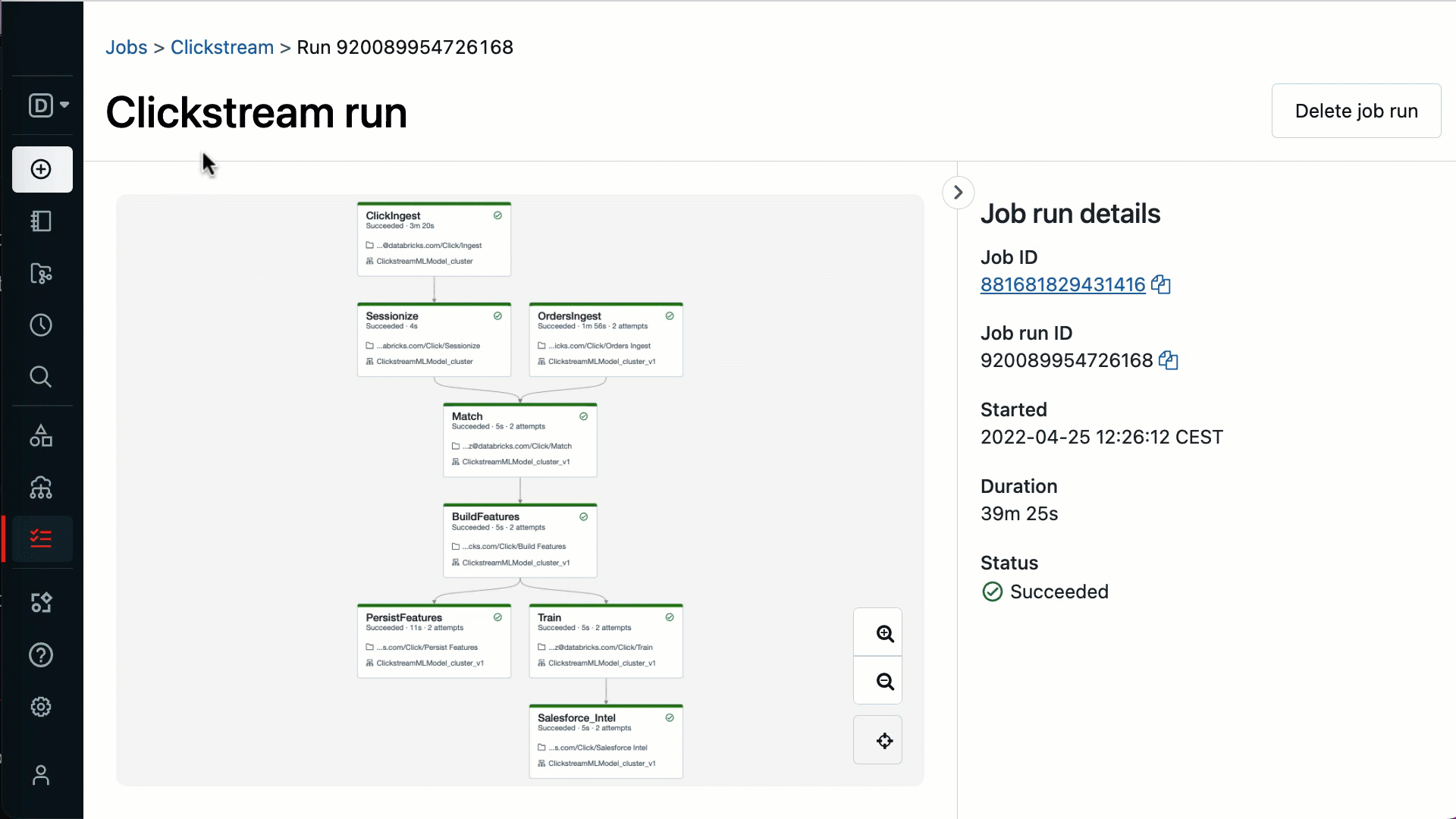
Real-time monitoring with actionable insights - The native integration with the lakehouse means getting full visibility into each task running in every workflow in real-time. When tasks fail, get notified immediately with alerts that give you verbose information, helping you troubleshoot and recover quickly.
Proven reliability in production - Databricks Workflows is fully managed so there is no additional cost or maintenance required to operate it. With 99.95% uptime, Databricks Workflows is trusted by thousands of organizations running millions of production workloads every day. Access to job clusters and the ability to share clusters between tasks also means efficient resource utilization and cost saving.
A Year of Innovation for Databricks Workflows
Since announcing Databricks Workflows a year ago, we've enabled more and more capabilities to allow Databricks users to get more control over their orchestrated workflows, handle more use cases and get better outcomes. Some of these innovations include:
- Triggers - The ability to trigger workflows on a schedule, file arrival or run them continuously
- Support for many new task types, including:
- Databricks SQL dashboards, queries and alerts
- SQL files
- dbt projects
- Context sharing - The ability to share context between tasks in a workflow
- Better alerting - with new notification capabilities
- Improved user interface
Orchestration Done Right
More and more organizations are building their data and AI solutions on the Databricks Lakehouse and taking advantage of the benefits of Databricks Workflows. Some great examples of Databricks customers doing orchestration right include:

Building a self service data platform to help data teams scale
Ahold Delhaize, one of the world's largest food and consumables retailers, is using data to help their customers eat well, save time and live better. The company moved away from Azure Data Factory as an orchestrator and used Databricks Workflows to build a self-service data platform that allows every data team to easily orchestrate their own unique pipeline. Leveraging cheaper automated job cluster and cluster reuse, the company was also able to reduce costs while accelerating deployment times.

Simplifying ETL orchestration
YipitData provides accurate granular insights to hundreds of investment funds and innovative companies. Generating these insights requires the processing of billions of data points with complex ETL pipelines. The company faced challenges with their existing Apache Airflow orchestrator including the significant time commitment required from data engineers to maintain and operate an external complex application outside of the Databricks platform. The company moved to Databricks Workflows and was able to simplify the user experience for analysts in the company, making it easier to onboard new users.

Breaking silos and improving collaboration
Wood Mackenzie offers customized consulting and analysis services in the energy and natural resources sectors. Data pipelines that power these services ingest 12 Billion data points every week and consist of multiple stages, each having a different owner in the data team. By standardizing the way the team orchestrates these ETL pipelines using Databricks Workflows, the data team was able to introduce more automation that reduced the risk of potential issues, improve collaboration and incorporate CI/CD practices that added more reliability and improved productivity leading to cost savings and to 80-90% reduction in processing time.
Get started
- Webpage: Databricks Workflows - Learn more about Databricks Workflows.
- Quickstart: Create your first workflow - Step-by-step instructions to get you started with your first workflow in just a few minutes.
- Webinar: Building Production-Ready Data Pipelines on the Lakehouse - Learn about the challenges of bringing data pipelines into production and how Delta Lake, Databricks Workflows and Delta Live Tables can help you tackle these challenges.
- Ebook: The Big Book of Data Engineering 2nd Edition - Get a collection of best practices for data engineering with real-world examples and code references you can use.
Join us at Data and AI Summit
Data and AI Summit which will happen in San Francisco June 26th-29th, 2023 is a great opportunity to learn more about the latest and greatest from the data and AI community. Specifically for Databricks Workflows, you can attend these sessions to get a better overview, see some demos and get a sneak preview of new features that are expected on the roadmap:
- Introduction to Data Engineering on the lakehouse
- Seven things you didn't know you can do with Databricks Workflows
- What's new in Databricks Workflows
Register now! To attend physically or virtually
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.