Technical Guide
Databricks DLT: Getting Started Guide
Note - at Data + AI Summit in June 2025, Databricks released Lakeflow. Lakeflow unifies data engineering with Lakeflow Connect, Lakeflow Declarative Pipelines (previously known as DLT), and Lakeflow Jobs (previously known as Workflows). We are currently working on a brand-new Declarative Pipelines guide - please stay tuned!
What Is DLT?
DLT is a declarative framework for building reliable, maintainable and testable data pipelines. It allows data engineers and analysts to define data transformations using SQL (or Python) and automatically manages the underlying infrastructure and data flow.
DLT introduces a new paradigm of data engineering that focuses on describing the transformations you want to perform on your data, rather than the specific steps to do so. It handles streaming data (continuous data processing), automatically scales to match your workload, and includes built-in quality controls and error handling.
DLT with serverless compute eliminates the need to manage compute resources while providing automatic, cost-effective scaling based on slot utilization. This serverless architecture brings many advanced capabilities, such as incremental refresh for materialized views, vertical autoscaling and stream pipelining.
These advanced features, combined with reduced operational overhead, faster spin-up times and automatic infrastructure updates, allow you to focus solely on your data transformations and business logic.
Introduction
In this guide, you’ll create and run your first DLT pipeline using the sample NYC taxi dataset. We’ll explore the medallion architecture, streaming tables and materialized views, and implement data quality checks using DLT expectations.
This is a beginner’s tutorial with hands-on instructions to execute in your own Databricks workspace (you can request a free 14-day trial).
If you prefer to avoid exploring DLT hands-on, you can still browse through this tutorial to learn about DLT concepts and best practices from a data engineering perspective without executing the steps. Alternatively, you can take a guided product tour where no account is required or watch one of many recorded video demos on the Databricks demo center.
Our Demo Example
The demo example in this guide illustrates DLT functionality using the well-known NYC taxi trip dataset. This public dataset is also available at Kaggle.
The pipeline processes streaming data through a medallion architecture consisting of Bronze, Silver and Gold layers. In the Bronze layer, raw taxi trip data is ingested, with a basic data quality check applied to ensure trip distances are positive. The Silver layer creates two tables: one identifying potentially suspicious rides based on fare and distance criteria, and another calculating weekly average fares and trip distances. Finally, the Gold layer shows the top three highest-fare rides, combining information from the Silver layer tables.
This guide covers all the fundamental data engineering skills and concepts: DLT can handle streaming data processing, implement data quality checks and create analytics-ready views. It provides a practical demonstration of how to structure a data pipeline using the medallion architecture, progressively refining and analyzing data as it moves through each layer.
The guide demonstrates DLT’s integration with Unity Catalog, showing how to set up data lineage and governance. Finally, it touches on how Databricks Assistant enhances data engineering by integrating data intelligence, helping with query optimization and pipeline improvements.
OPTIONAL: Understanding the Medallion Architecture
The medallion architecture is a data design pattern used to logically organize data in a lakehouse, aiming to incrementally and progressively improve the structure and quality of data as it flows through each layer. This pattern typically includes three layers:
- Bronze (raw): This layer contains raw data ingested from various sources. In our pipeline, this is represented by the taxi_raw_records table. It’s best practice to avoid complex rules or transformations at this stage, focusing instead on ingesting all data as is so no data is lost due to potential errors in complex processing rules.
- Silver (cleaned and conformed): This layer provides a more refined view of our data. Tables have some level of cleansing and conforming applied to them. In our pipeline, we have two Silver tables: flagged_rides and weekly_stats.
- Gold (curated business-level): This layer provides curated data ready for consumption by business users, analytics and ML. It often includes aggregations and joins between different tables. In our pipeline, this is represented by the top_n view.
This architecture is a guideline for better structuring data pipelines but should be adapted to fit specific organizational needs. Some projects might benefit from additional layers, while others might combine or omit layers.
Create a New Notebook
Let’s get started and create a new notebook for our data pipeline!
- In your Databricks workspace, click “+New” in the left sidebar and select Notebook.
- Name the notebook “NYTaxi Pipeline SQL.”
- Set the notebook’s default language to SQL next to its name. We want to code the pipeline in SQL for simplicity.
- Copy and paste the following code into your new SQL notebook.
- OPTIONAL: You can copy the sections Bronze, Silver and Gold into different notebook cells to enhance the structure and clarity of the SQL code.
- OPTIONAL: If you are experienced working with GitHub repositories, you can also clone the notebook from GitHub. Use https://github.com/databricks/tmm as the GitHub repository and “NY-Taxi-Fares” for the cone pattern. For beginners, we recommend copying to SQL as described above.
Streaming Tables and Materialized Views
In this DLT pipeline, we use both streaming tables and materialized views:
- Streaming tables (taxi_raw_records, flagged_rides): These tables are designed to ingest or process new data as it arrives continuously. They use the STREAMING TABLE syntax and are ideal for real-time data processing of streaming data from append-only data sources.
Streaming tables support incremental processing, efficiently handling new data without reprocessing the entire dataset.
- Materialized views (weekly_stats, top_n): These are precomputed views that store the result. They’re updated automatically when the underlying data changes.
When using serverless compute, materialized views support incremental updates. This means the system aims to process only the changed data, which can significantly improve pipeline efficiency. Full reprocessing only occurs when necessary.
Materialized views are ideal for complex aggregations or joins that you want to compute ahead of time to speed up querying or improve dashboard performance.
Data Quality Expectations
Expectations are a way to define data quality rules directly in your pipeline. Expectations filter out problematic data before it reaches your tables. In our example, we have one expectation:
CONSTRAINT valid_distance EXPECT (trip_distance > 0.0) ON VIOLATION DROP ROW
This expectation is applied to the taxi_raw_records table. It ensures that only records with a positive trip distance are included in the table. Any rows violating this constraint are dropped (DROP action). Alternatively, they could be retained with a warning (WARN action), or the pipeline could be set to fail if any violations occur (FAIL action), depending on how strictly you want to enforce this data quality rule.
Data quality is more than just a keyword in a pipeline definition. The Databricks Data Intelligence Platform ensures data quality at three distinct levels:
- Architectural level: The medallion architecture (MA) ensures data quality by progressively refining data through Bronze, Silver and Gold layers, each with increasing levels of cleansing and validation.
- Code level: Data quality constraints, implemented as DLT expectations, prevent bad data from flowing into our tables. You can add more expectations at each layer for progressively stricter data quality controls.
- Transactional level: The underlying Delta Lake format ensures data quality through ACID (atomicity, consistency, isolation, durability) transactions, guaranteeing data integrity even in case of failures or concurrent operations.
This multilayered approach to data quality — architectural, code-level and transactional — provides a robust framework for maintaining data integrity throughout the entire data pipeline process.
Define the Pipeline Setting
After creating your notebook with the pipeline code in SQL, you need to configure the core pipeline settings, as both are required for running the pipeline. The pipeline code in your SQL notebook defines what the pipeline does — the data transformations, quality checks and the tables created. The pipeline settings determine how the pipeline runs — which notebooks it consists of, its environment, the serverless compute setting, and execution parameters. Together, these components form an executable DLT pipeline.
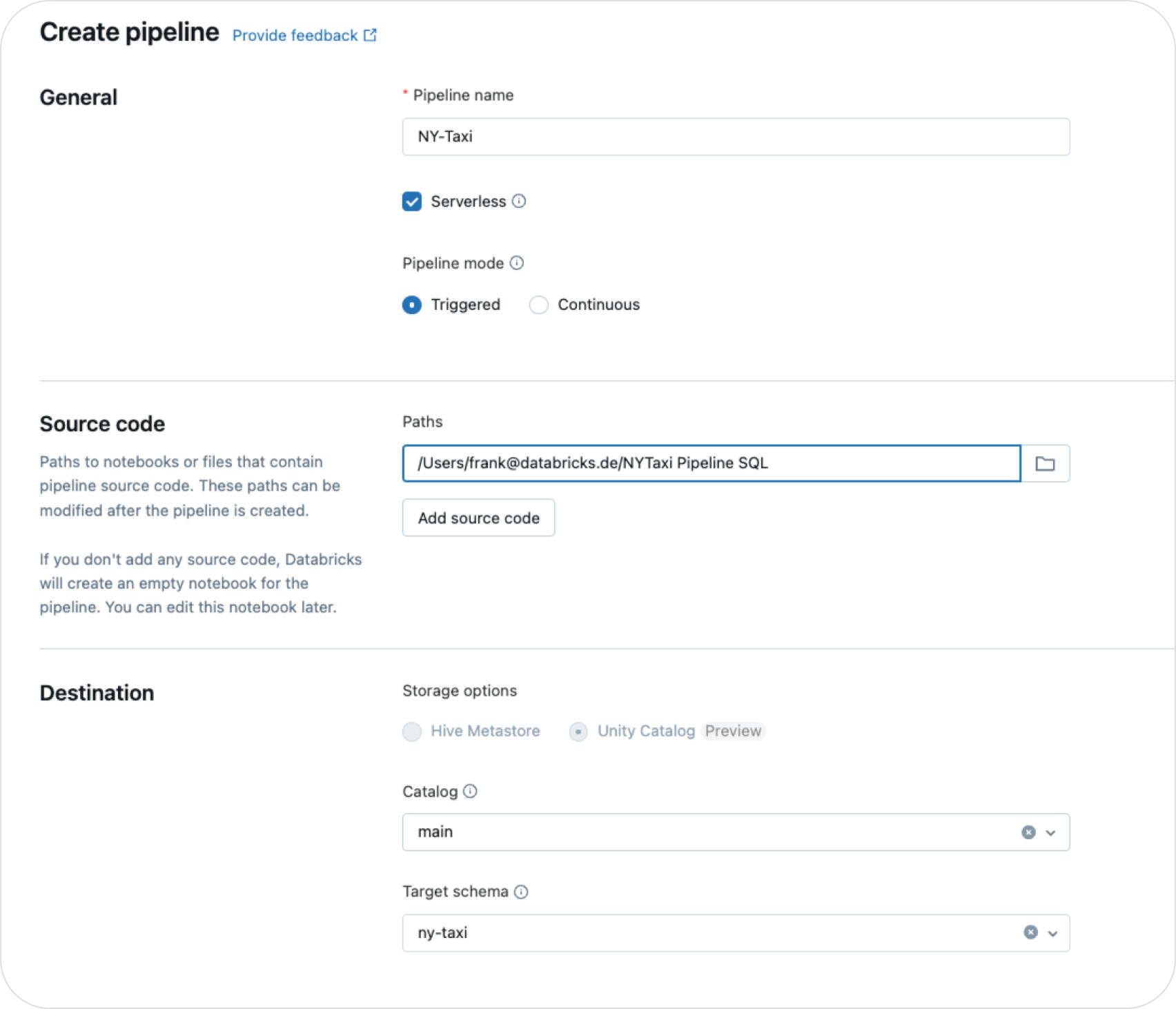
- In your Databricks workspace, under “Data Engineering,” click “Create Pipelines.”
- Under pipeline settings, enter a descriptive name for your pipeline: “NY-Taxi.”
- Considering the advantages we discussed about DLT with serverless compute, choose “Serverless” as the compute option.
- DLT pipelines can run in triggered or continuous mode. We use triggered mode here, which runs the pipeline on demand or on a schedule driven by Databricks Workflows. This setting gives you more control over pipeline execution than continuous mode. So leave the “Pipeline mode” setting as “Triggered.”
- Under “Source Code” define the path to the notebook you created in the previous step.
- Databricks Unity Catalog uses the three-level namespace structure catalog.schema.object to organize and manage data assets across multiple workspaces and cloud environments. Objects at the third level can include streaming tables, materialized views, functions and other data assets, such as AI models, allowing for comprehensive data organization and governance. This hierarchical structure enhances data discovery, simplifies access control and improves overall data governance, allowing organizations to manage their data more effectively at scale.
Under “Destination” select an existing Unity Catalog name (e.g., “main”) and a target schema to be created, such as “nytaxi”. Details about using DLT with UC can be found in the official documentation. - Leave all the other settings as default for now.
Developer Experience and the Pipeline Graph
Go back to the SQL notebook that defines the pipeline and see that the notebook can now be associated with the pipeline.
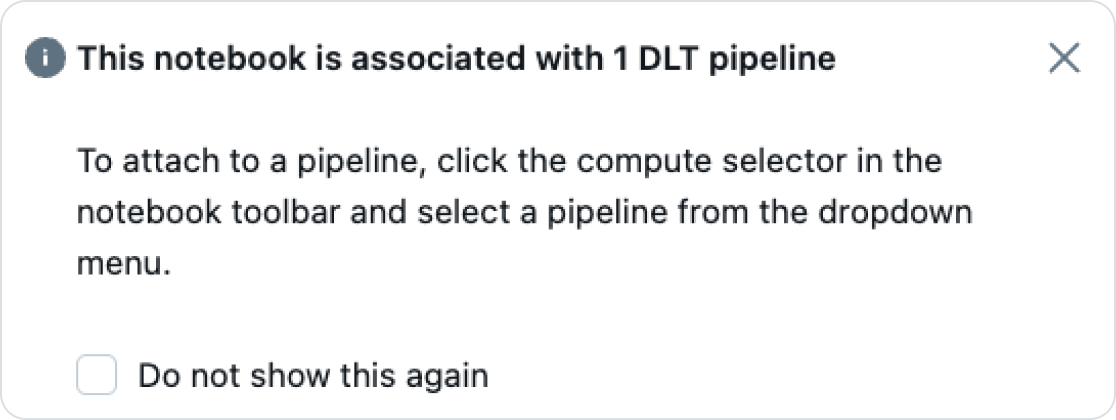
- Attach it to the “NYTaxi” pipeline.
After the notebook is attached to the pipeline, the notebook serves as a centralized control center, displaying the code, pipeline graph and pipeline logs in a single interface. This integrated environment allows you to validate (syntax check pipelines without processing data) and run pipelines directly, streamlining the development and execution process:
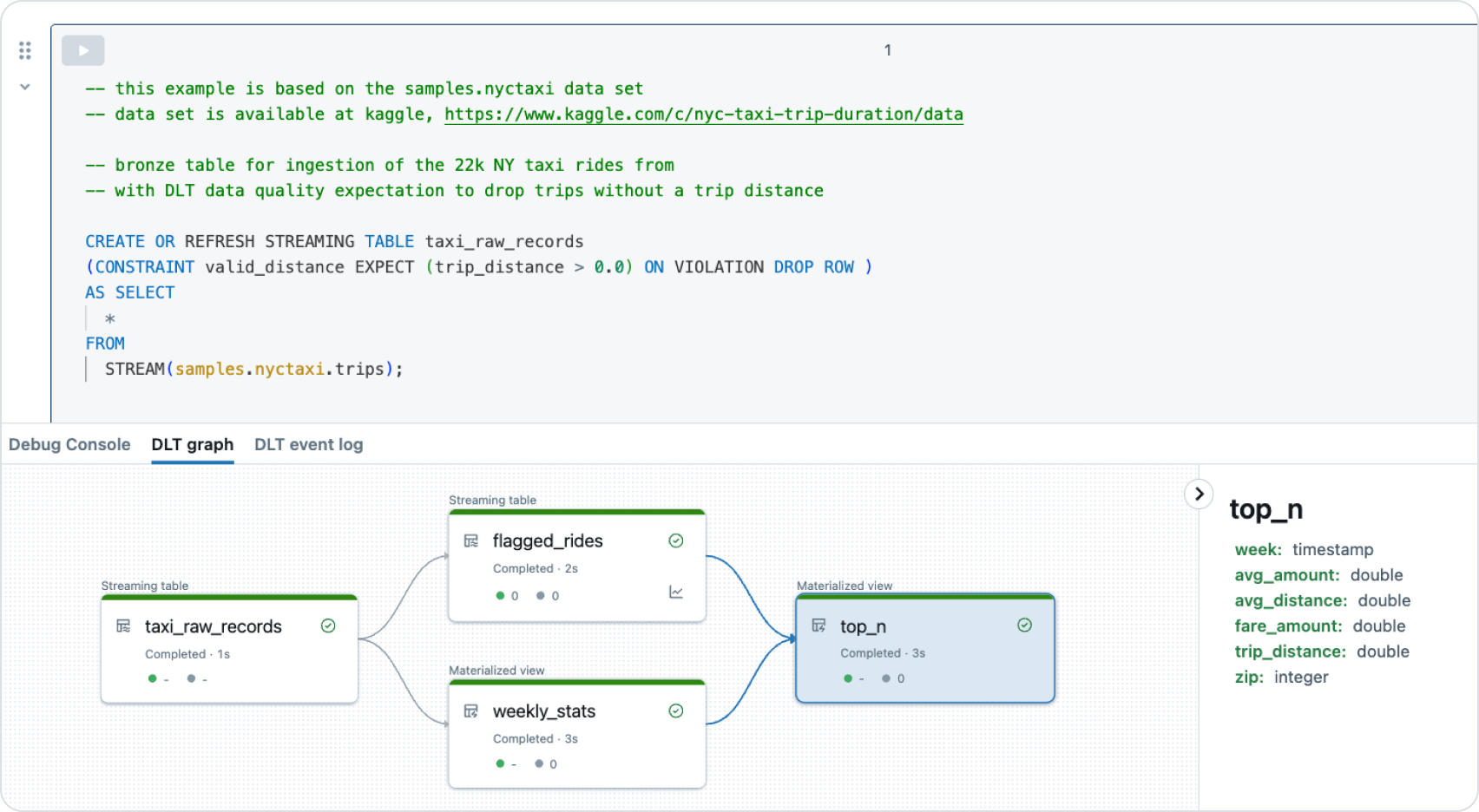
- Click the “Start” button to run the pipeline.
- Once the pipeline is running, you can see the pipeline graph in your notebook.
- OPTIONAL: Switch to the “DLT event log” and explore its entries. All the data from the event log is persisted in Delta tables.
- OPTIONAL: Click the “top_n” materialized view to see the column data types.
Sample Data and Lineage in Unity Catalog
Follow the steps below to examine the data produced by your pipeline and visualize its lineage. This allows you to inspect sample data, view table details and explore the end-to-end data lineage of your pipeline objects.
- Click the connected pipeline “NY-Taxi” next to the “Share” button on the top right, select “NY-Taxi” and then “Open in DLT UI”.
- In the pipeline view, select one of the tables, e.g., “top_n.”
- On the right-hand side, click the “Target Table Link.”
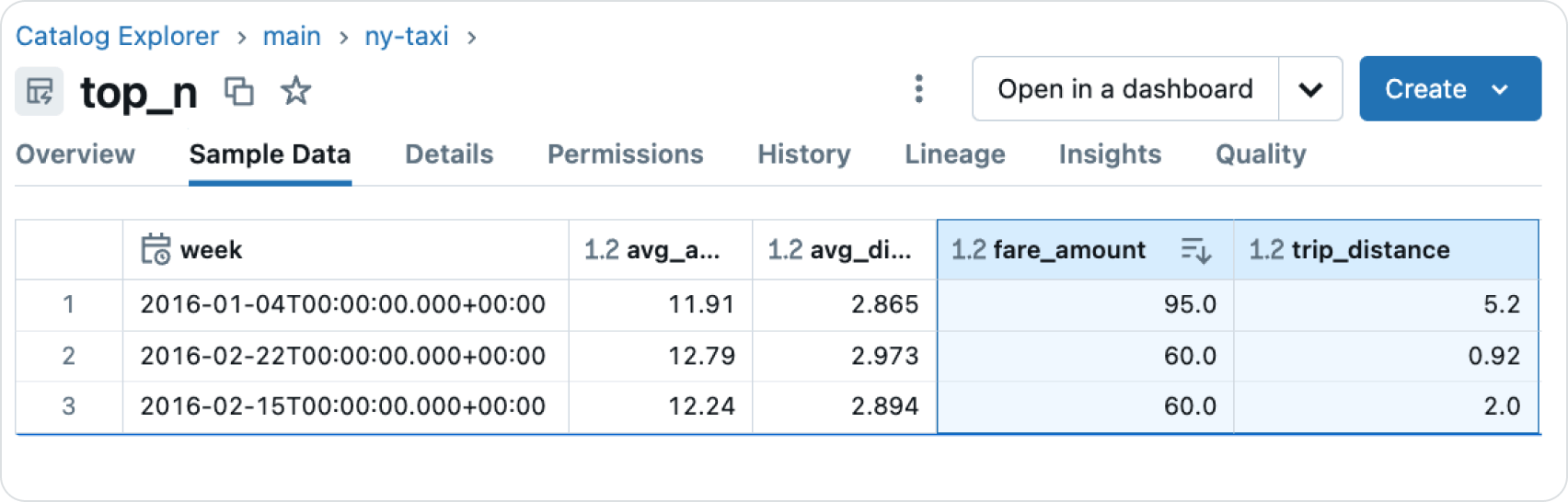
- Explore the various tabs for “Details” etc., then select the “Sample Data” tab.
- Under “Sample Data”, you can see three super expensive taxi trips, e.g., someone paid $95 for five miles.
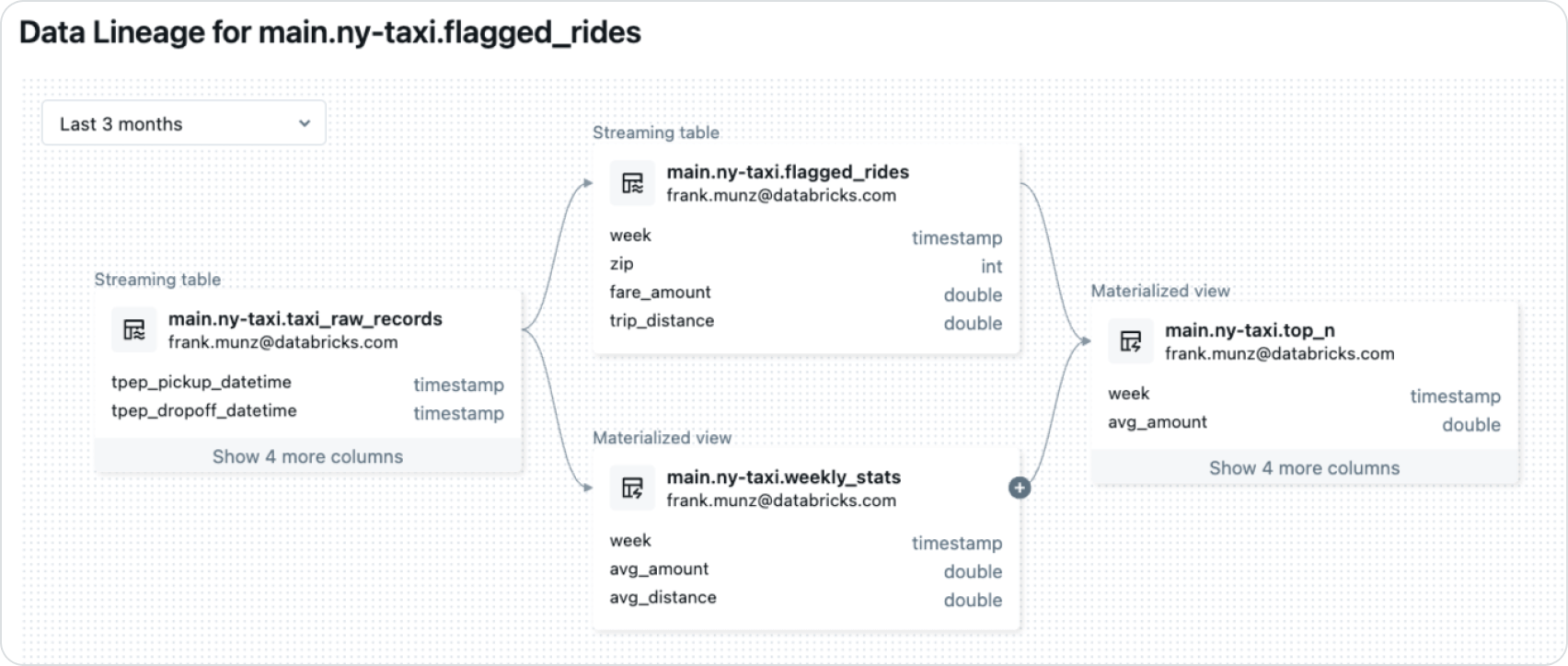
6. Then click the lineage tab and drill open the connection by clicking on the “+” sign. You will see a complete, end-to-end lineage view. While our example focuses on data pipelines, this view would also include volumes and AI models for more complex real-world scenarios.
AI-Supported Data Engineering With Databricks Assistant
Databricks Assistant is an AI-powered tool designed to enhance productivity in data engineering and analytics workflows. It offers intelligent code completion, query optimization suggestions and natural language interactions to help users write, debug, document, explain and improve their data pipelines.
- Open your notebook again with the pipeline definition in SQL.
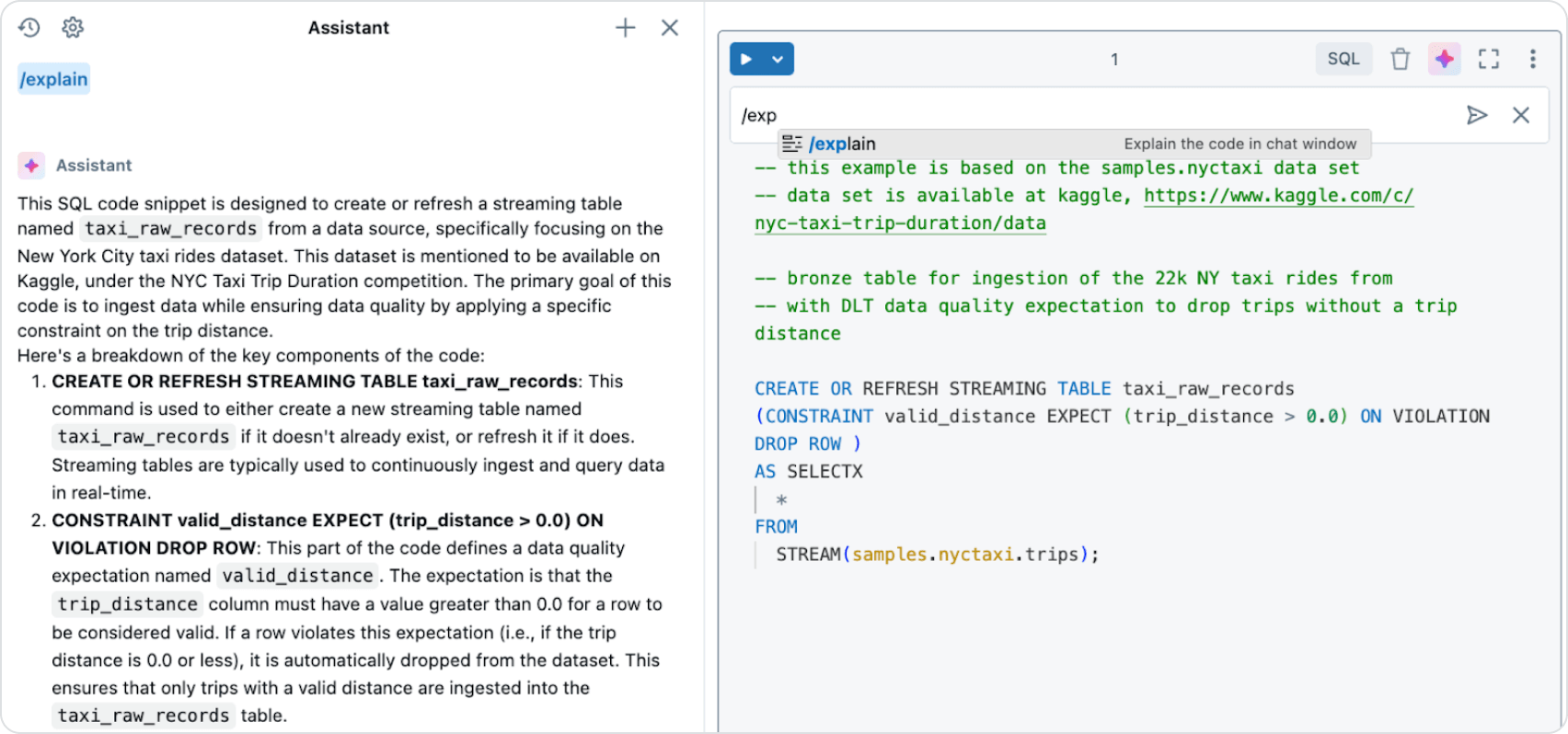
- Click the first notebook cell’s Assistant symbol (the bluish/reddish star).
- In the Assistant command line, type “/explain.” The Assistant will explain the code, including streaming tables and materialized views. Does it match the definition from above?
- OPTIONAL: Replace the SELECT statement with “SELECTX” and try the “fix” command.
Databricks Assistant is context-aware and integrates seamlessly with Unity Catalog. It learns metadata such as table and column names to provide more accurate and relevant suggestions tailored to your specific data environment.
Congratulations!
You’ve now created, run and analyzed a DLT pipeline demonstrating streaming data processing, data quality checks and the creation of analytics-ready views. Not only have you gained insights into DLT and the taxi trip data, but you’ve also likely learned how expensive a ride in the Big Apple can be if things go wrong — perhaps it’s time to consider the subway!
As you become more comfortable with DLT, you can expand this pipeline with more complex transformations, additional data sources and more comprehensive data quality checks. Consider exploring advanced features like change data capture for efficient update processing from third-party systems or ingesting data from various streaming sources such as Apache Kafka, Amazon Kinesis, Google Pub/Sub or Apache Pulsar to enhance your data pipelines further.
LakeFlow
During Data + AI Summit, we introduced LakeFlow, the unified data engineering solution consisting of LakeFlow Connect (ingestion), LakeFlow Pipelines (transformation) and LakeFlow Jobs (orchestration). As we evolve DLT, all of the capabilities we discussed above will become part of the new LakeFlow solution.
Additional Resources
- DLT on Databricks
- DLT Documentation
- Databricks Demo Center with DLT video demos, product tours and tutorials
- Databricks Events with quarterly hands-on DLT workshops
- The NY Taxi DLT SQL example on GitHub