What are Large Language Models (LLM)?
Neural networks with billions of parameters trained on massive text corpora via self-supervised learning, capable of generating human-like text for NLP tasks
- Large language models are AI systems trained on massive collections of text so they can generate and understand human language. They perform tasks like answering questions, summarizing documents, writing content and supporting chat based interactions. Because of their size and training data, large language models can generalize across many language tasks but still require careful, responsible use.
What are large language models (LLMs)?
Language models are a type of generative AI (GenAI) that use natural language processing (NLP) to understand and generate human language. Large language models (LLMs) are the most powerful of these. LLMs are trained from massive datasets using advanced machine learning (ML) algorithms to learn the patterns and structures of human language and generate text responses to written prompts. Examples of LLMs include BERT, Claude, Gemini, Llama and the Generative Pretrained Transformer (GPT) family of LLMs.
LLMs have significantly surpassed their predecessors in performance and ability in a variety of language-related tasks. Their ability to generate complex, nuanced content and automate tasks for human-like results is driving advancements in various fields. LLMs are being widely integrated into the business world for impact across a variety of environments and business uses, including automating support, surfacing insights and generating personalized content.
Core LLM AI and language capabilities include:
- Natural language understanding: LLMs can understand the nuances of human language, including context, semantics and intent.
- Multimodal content generation: LLMs can produce human-like text for various purposes, from coding to creative writing, as well as images, speech and more.
- Question answering: LLMs can intelligently answer open-ended questions.
- Scalability: LLMs can leverage graphics processing unit (GPU) capabilities to efficiently take on large-scale language tasks and adapt to growing business needs.
How do LLMs work?
Most LLMs are built using a transformer architecture. They work by breaking input text into tokens (subword units), embedding those tokens into numerical vectors and using attention mechanisms to understand relationships across the input. They then predict the next token in a sequence to generate coherent outputs.
What does it mean to pretrain LLMs?
Pretraining an LLM model refers to the process of training it on a large body of data, such as text or code, without using any prior knowledge or weights from an existing model. The output of full pretraining is a base model that can be directly used or further fine-tuned for downstream tasks.
Pretraining ensures that the foundational knowledge of the model is tailored to your specific domain. The result is a custom model that is differentiated by your organization’s unique data. However, pretraining is typically the largest and most expensive type of training and is not typical for most organizations.
What does it mean to fine-tune LLMs?
Fine-tuning is the process of adapting a pretrained LLM on a comparatively smaller dataset that is specific to an individual domain or task. During the fine-tuning process, the LLM continues training for a short time, possibly by adjusting a relatively smaller number of weights compared to the entire model.
The two most common forms of fine-tuning are:
Supervised instruction fine-tuning: This approach involves continued training of a pretrained LLM on a dataset of input-output training examples, typically conducted with thousands of training examples.
Continued pretraining: This fine-tuning method does not rely on input and output examples but instead uses domain-specific unstructured text to continue the same pretraining process (such as next token prediction and masked language modeling).
Fine-tuning is important because it allows an organization to take a foundation LLM and train it with its own data for greater accuracy and customization for the company’s domain and workloads. This also gives the organization control to govern the data used for training so you can make sure you’re using AI responsibly.
Neural networks and transformer architecture
LLMs are built on deep learning, a form of AI in which large amounts of data are fed into a program to train it, based on probability. With exposure to massive datasets, LLMs can train themselves to recognize language patterns and relationships without explicit programming, with self-learning mechanisms to continuously improve accuracy.
The foundation of LLMs is artificial neural networks, inspired by the structure of the human brain. These networks consist of interconnected nodes arranged in layers, including an input layer, an output layer and one or more layers in between. Each node processes and transmits information to the next layer based on learned patterns.
LLMs use a type of neural network called a transformer model. These groundbreaking models can look at an entire sentence all at once, in contrast to older models that process words sequentially. This makes them able to understand language faster and more efficiently. Transformer models use a mathematical technique called self-attention, which assigns varying importance to different words in a sentence, enabling the model to grasp nuances in meaning and understand context. Positional encoding helps the model understand the importance of word order within a sentence, which is essential to comprehending language. The transformer model enables LLMs to process vast amounts of data, learn contextually relevant information and generate coherent content.
A simplified version of the LLM training process

Learn more about transformers, the foundation of every LLM
What are the use cases for LLMs?
LLMs can drive business impact across use cases and different industries. Example use cases include:
- Chatbots and virtual assistants: LLMs are used to power chatbots to give customers and employees the ability to have open-ended conversations to help with customer support, website lead follow-up and personal assistant services.
- Content creation: LLMs can generate different types of content, such as articles, blog posts and social media updates.
- Code generation and debugging: LLMs can generate useful code snippets, identify and fix errors in code and complete programs based on input instructions.
- Sentiment analysis: LLMs can automatically understand the sentiment of a piece of text to gauge customer satisfaction.
- Text classification and clustering: LLMs can organize, categorize and sort large volumes of data to identify common themes and trends to support informed decision-making.
- Language translation: LLMs can translate documents and web pages into different languages to reach different markets.
- Summarization and paraphrasing: LLMs can summarize papers, articles, customer calls or meetings and concisely capture the most important points.
- Security: LLMs can be used in cybersecurity to identify threat patterns and automate responses.
The agentic AI playbook for the enterprise

What are customer examples where LLMs have been deployed effectively?
JetBlue
JetBlue has deployed “BlueBot,” a chatbot that uses open source generative AI models complemented by corporate data, powered by Databricks. This chatbot can be used by all teams at JetBlue to get access to data governed by role. For example, the finance team can see data from SAP and regulatory filings, but the operations team will only see maintenance information.
Chevron Phillips
Chevron Phillips leverages generative AI solutions powered by open source models like Dolly from Databricks to streamline document process automation. These tools transform unstructured data from PDFs and manuals into structured insights, enabling faster and more accurate data extraction for operations and market intelligence. Governance policies ensure productivity and risk management while maintaining traceability.
Thrivent Financial
Thrivent Financial is leveraging generative AI and Databricks to speed up searches, deliver clearer and more accessible insights and boost engineering productivity. By bringing data together under a single platform with role-based governance, the company is creating a secure space where teams can innovate, explore and work more efficiently.
Why are LLMs suddenly becoming popular?
There are many recent technological advancements that have propelled LLMs into the spotlight:
- Advancement of machine learning technologies: LLMs utilize many advancements in ML techniques. The most notable is the transformer architecture, which is the underlying architecture for most LLM models.
- Increased accessibility: The release of ChatGPT opened the door for anyone with internet access to interact with one of the most advanced LLMs through a simple web interface, allowing the world to understand the power of LLMs.
- Increased computational power: The availability of more powerful computing resources, like graphics processing units (GPUs) and better data processing techniques, allowed researchers to train much larger models.
- Quantity and quality of training data: The availability of large datasets and the ability to process them have dramatically improved model performance. For example, GPT-3 was trained on big data (about 500 billion tokens) that included high-quality subsets such as the WebText2 dataset (17 million documents), which contains publicly crawled web pages with an emphasis on quality.
How do I customize an LLM with my organization’s data?
There are four architectural patterns to consider when customizing an LLM application with your organization’s data. These techniques are outlined below and are not mutually exclusive. Rather, they can (and should) be combined to take advantage of the strengths of each.
Regardless of the technique selected, building a solution in a well-structured, modularized manner ensures organizations will be prepared to iterate and adapt. Learn more about this approach and more in The Big Book of Generative AI.
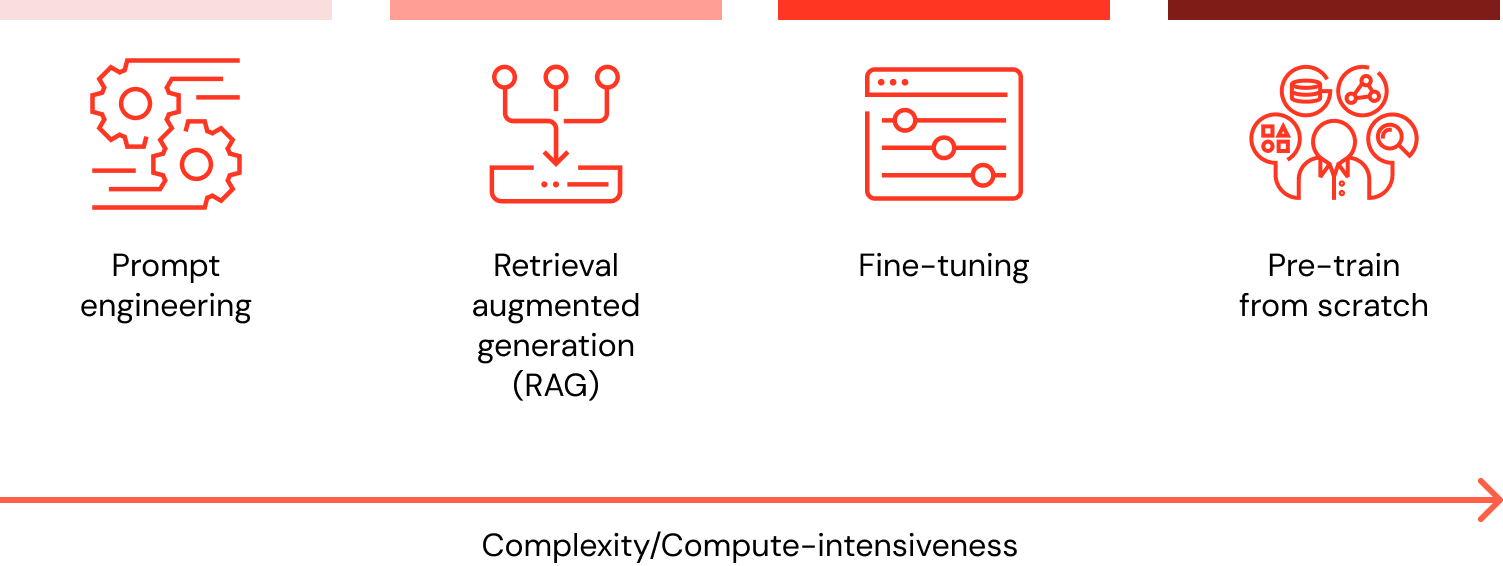
| Method | Definition | Primary use case | Data requirements | Advantages | Considerations |
|---|---|---|---|---|---|
| Crafting specialized prompts to guide LLM behavior | Quick, on-the-fly model guidance | None | Fast, cost-effective, no training required | Less control than fine-tuning | |
| Combining an LLM with external knowledge retrieval | Dynamic data sets and external knowledge | External knowledge base or database (e.g., vector database) | Dynamically updated context, enhanced accuracy | Increases prompt length and inference computation | |
| Adapting a pre-trained LLM to specific data sets or domains | Domain or task specialization | Thousands of domain-specific or instruction examples | Granular control, high specialization | Requires labeled data, computational cost | |
| Training an LLM from scratch | Unique tasks or domain-specific corpora | Large data sets (billions to trillions of tokens) | Maximum control, tailored for specific needs | Extremely resource-intensive |

What does prompt engineering mean as it relates to LLMs?
Prompt engineering is the practice of adjusting the text prompts given to an LLM to elicit more accurate or relevant responses. Not every LLM model will produce the same quality, as prompt engineering is model-specific. The following are some generalized tips that work for a variety of models:
- Use clear, concise prompts, which may include an instruction, context (if needed), a user query or input and a description of the desired output type or format.
- Provide examples in your prompt (“few-shot learning”) to help the LLM understand what you want.
- Tell the model how to behave, such as telling it to admit if it cannot answer a question.
- Tell the model to think step-by-step or explain its reasoning.
- If your prompt includes user input, use techniques to prevent prompt hacking, such as making it very clear which parts of the prompt correspond to your instruction versus user input.
What does retrieval augmented generation (RAG) mean as it relates to LLMs?
Retrieval augmented generation, or RAG, is an architectural approach that can improve the efficacy of LLM applications by leveraging custom data. This is done by retrieving relevant data/documents relevant to a question or task and providing them as context for the LLM. RAG has shown success in support chatbots and Q&A systems that need to maintain up-to-date information or access domain-specific knowledge.
Learn more about RAG here.
What are the most common LLMs and how are they different?
The field of LLMs is crowded with many options to choose from. Generally speaking, you can group LLMs into two categories: proprietary models and open source models.
Proprietary models
Proprietary LLM models are developed and owned by private companies and typically require licenses to access. Perhaps the most high-profile proprietary LLM is GPT-4o, which powers ChatGPT, released in 2022 with much fanfare. ChatGPT provides a friendly search interface where users can feed prompts and typically receive a fast and relevant response. Developers can access the ChatGPT API to integrate it into their own applications, products or services. Other proprietary models include Google’s Gemini and Claude from Anthropic.
Open source models
Another option is to self-host an LLM, typically using a model that is open source and available for commercial use. The open source community has quickly caught up to the performance of proprietary models. Popular open source LLM models include Llama 4 from Meta and Mixtral 8x22B.
How to evaluate the best choice
The biggest considerations and differences in approach between using an API from a closed third-party vendor versus self-hosting your own open source (or fine-tuned) LLM model are future-proofing, managing costs and leveraging your data as a competitive advantage. Proprietary models can be deprecated and removed, breaking your existing pipelines and vector indexes, whereas open source models will be accessible to you forever. Open source and fine-tuned models can offer more choice and tailoring to your application, allowing better performance-cost trade-offs. Planning for future fine-tuning of your own models will allow you to leverage your organization’s data as a competitive advantage for building better models than are available publicly. Finally, proprietary models may raise governance concerns as these “black box” LLMs permit less oversight of their training processes and weights.
Hosting your own open source LLM models does require more work than using proprietary LLMs. MLflow from Databricks makes this easier for someone with Python experience to pull any transformer model and use it as a Python object.
How do I choose which LLM to use?
Evaluating LLMs is a challenging and evolving domain, primarily because LLMs often demonstrate uneven capabilities across different tasks. An LLM might excel in one benchmark, but slight variations in the prompt or problem can drastically affect its performance.
Some prominent tools and benchmarks used to evaluate LLM performance include:
- MLflow
- Provides a set of LLMOps tools for model evaluation.
- Mosaic Model Gauntlet
- An aggregated evaluation approach, categorizing model competency into six broad domains (shown below) rather than distilling to a single monolithic metric.
- Hugging Face gathers hundreds of thousands of models from open LLM contributors
- BIG-bench (Beyond the Imitation Game benchmark)
- A dynamic benchmarking framework, currently hosting over 200 tasks, with a focus on adapting to future LLM capabilities.
- EleutherAI LM Evaluation Harness
- A holistic framework that assesses models on over 200 tasks, merging evaluations like BIG-bench and MMLU, promoting reproducibility and comparability.
Also, read the Best Practices for LLM Evaluation of RAG Applications.
How do you operationalize the management of LLMs via large language model ops?
Large language model ops (LLMOps) encompass the practices, techniques and tools used for the operational management of LLMs in production environments.
LLMOps allows for the efficient deployment, monitoring and maintenance of LLMs. LLMOps, like traditional machine learning ops (MLOps), require a collaboration of data scientists, DevOps engineers and IT professionals. See more details of LLMOps here.
Where can I find more information about large language models (LLMs)?
There are many resources available to find more information on LLMs, including:
Training
- LLMs: Foundation Models From the Ground Up (EDX and Databricks Training) — Free training from Databricks that dives into the details of foundation models in LLMs
- LLMs: Application Through Production (EDX and Databricks Training) — Free training from Databricks that focuses on how to build LLM-focused applications with the latest and most well-known frameworks
eBooks
- The Big Book of Generative AI
- A Compact Guide to Fine-Tuning and Building Custom LLMs
- A Compact Guide to Large Language Models
Technical blogs
- Introducing Meta’s Llama 4 on the Databricks Data Intelligence Platform | Databricks Blog
- Serving Qwen Models on Databricks | Databricks Blog
- Best Practices for LLM Evaluation of RAG Applications
- Using MLflow AI Gateway and Llama 2 to Build Generative AI Apps
- Build High-Quality RAG Apps With Agent Bricks Custom Agents and Agent Evaluation, Model Serving and AI Search
- LLMOps: Everything You Need to Know to Manage LLMs
Next steps
- Contact Databricks to schedule a demo and talk to someone about your large language model (LLM) projects
- Read about Databricks’ offerings for LLMs
- Read more about the retrieval augmented generation (RAG) use case (the most common LLM architecture)
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.