Databricks Notebooks
Unified developer experience to build data and AI projects


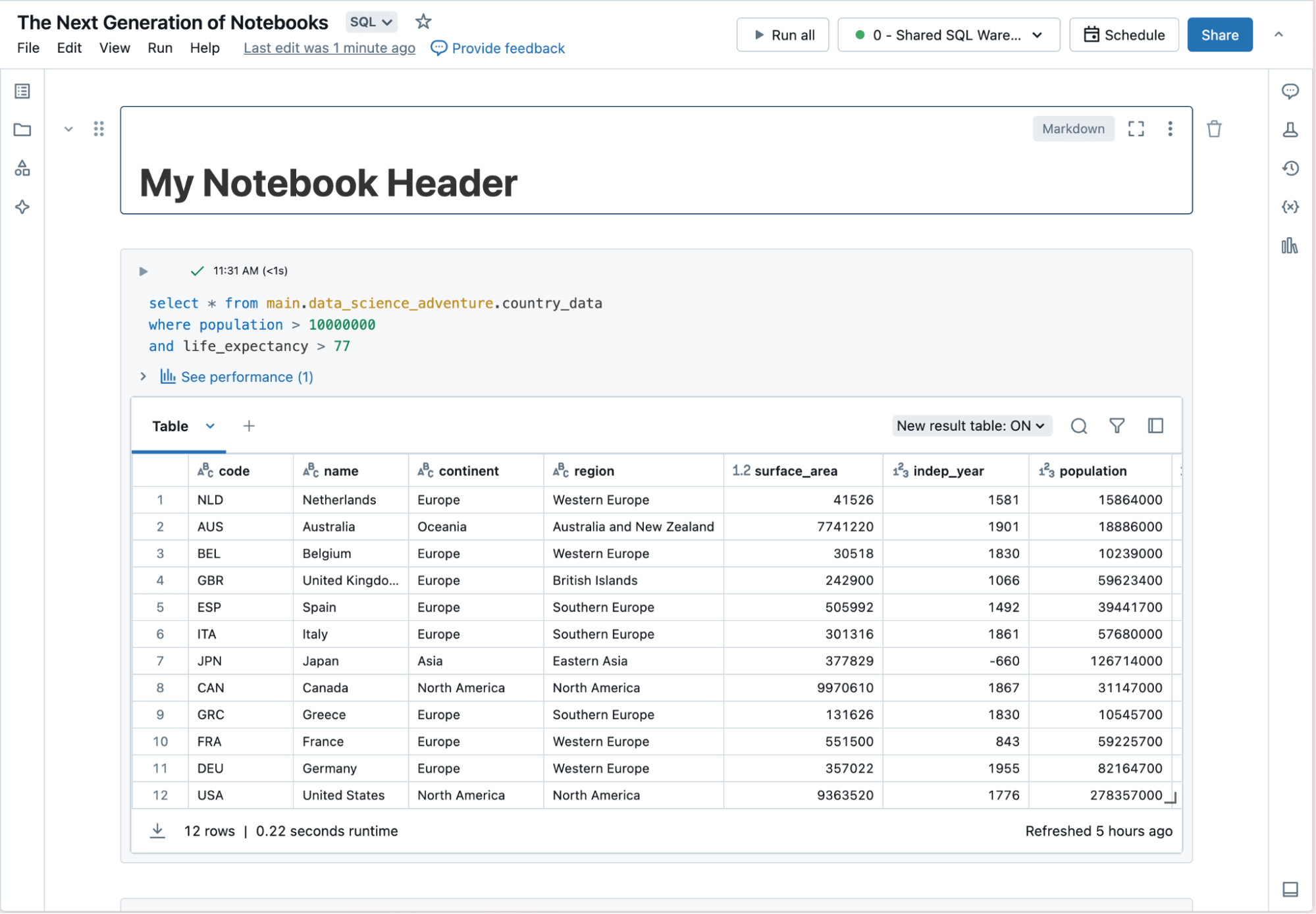
Databricks Notebooks simplify building data and AI projects through a fully managed and highly automated developer experience. Notebooks work natively with the Databricks Data Intelligence Platform to help data practitioners start quickly, develop with context-aware tools and easily share results.
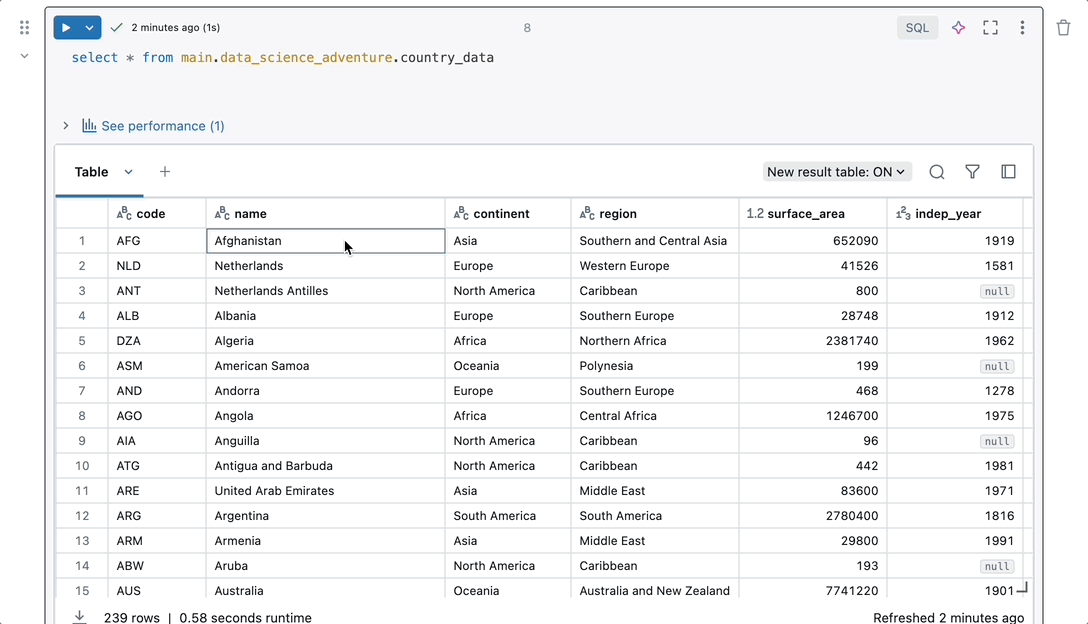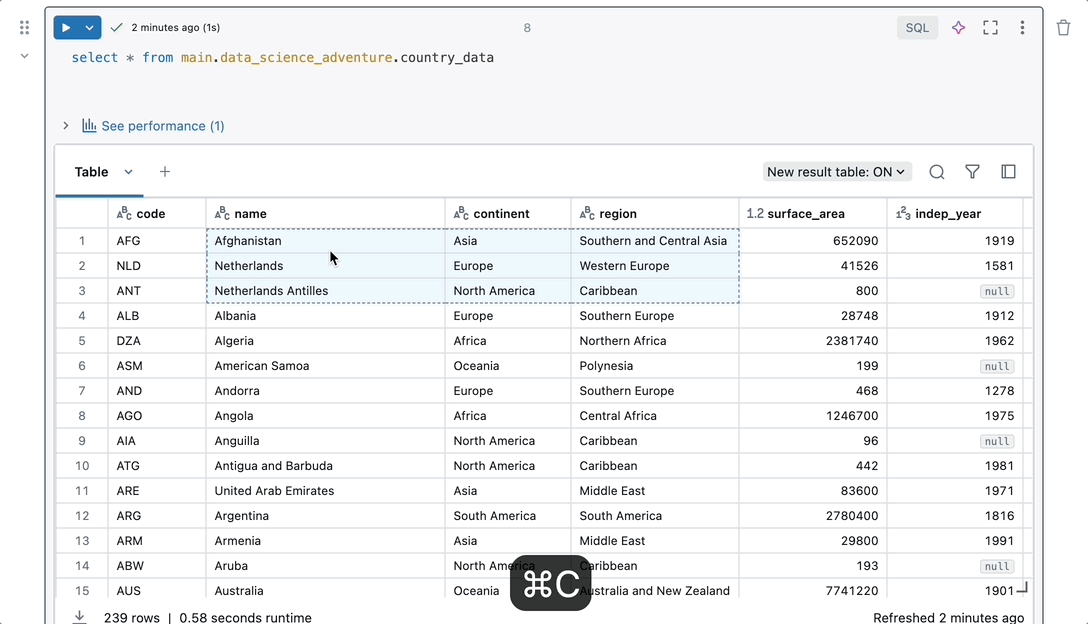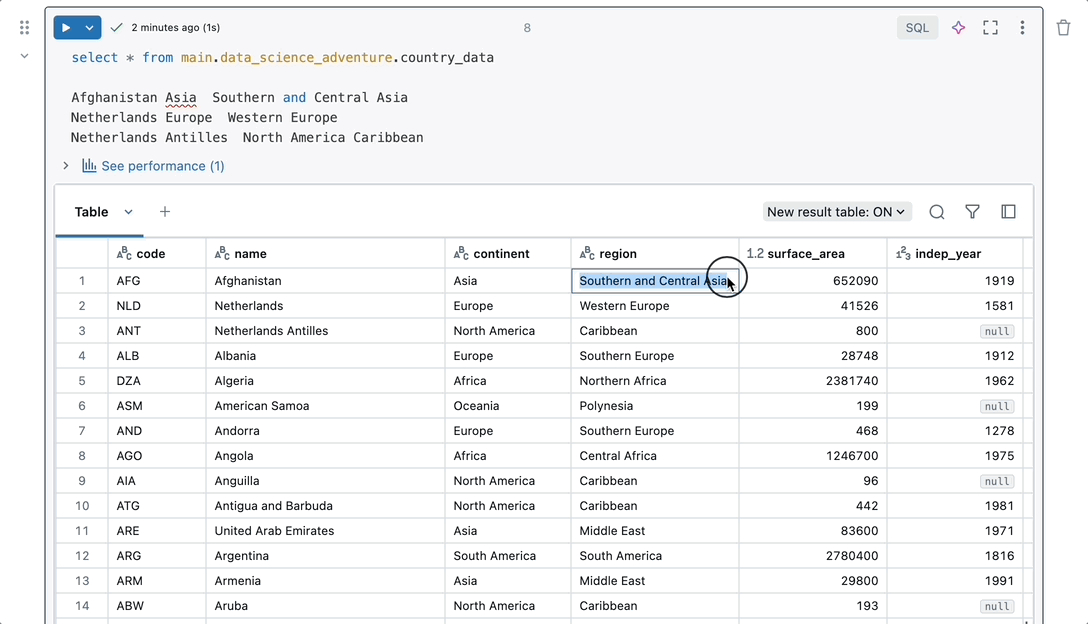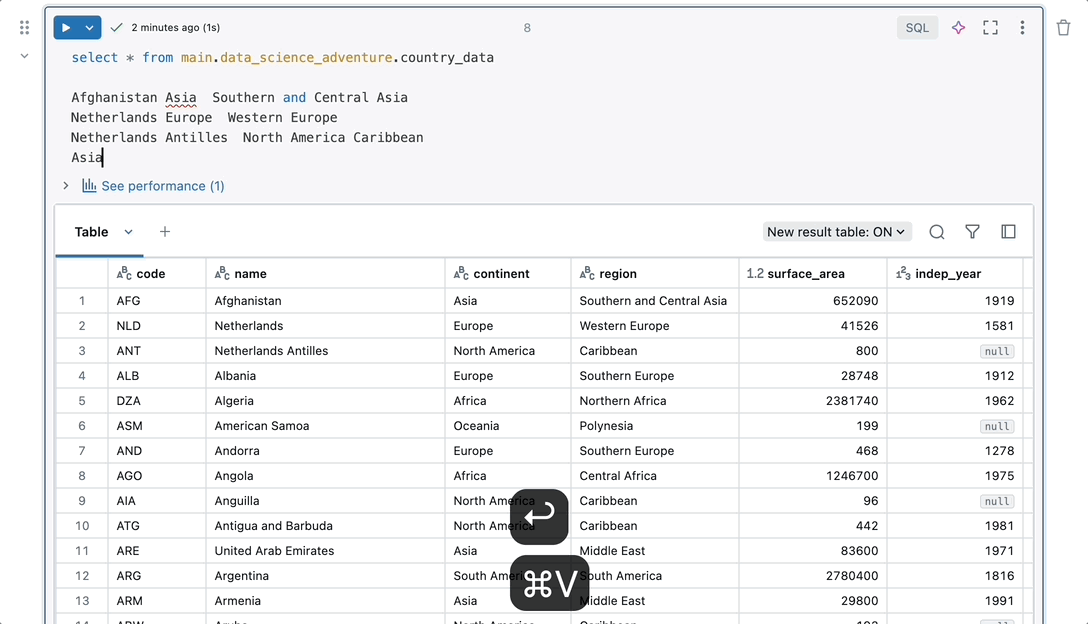
Seamless integration
Start your work without needing to set up and configure your workspace. Notebooks come with native features for the entire data journey in one place. You can access data, compute and visualization tools without additional setup so you can focus on analyzing your data.

Data Intelligence tools
Spend time on insights, not on boilerplate code. Notebooks tap into information about your data including lineage, related tables and popularity to surface suggestions relevant to your work. Notebooks include Databricks Assistant, a context-aware AI assistant that lets you query data through a conversational interface to make you more productive.
Collaborative workspace
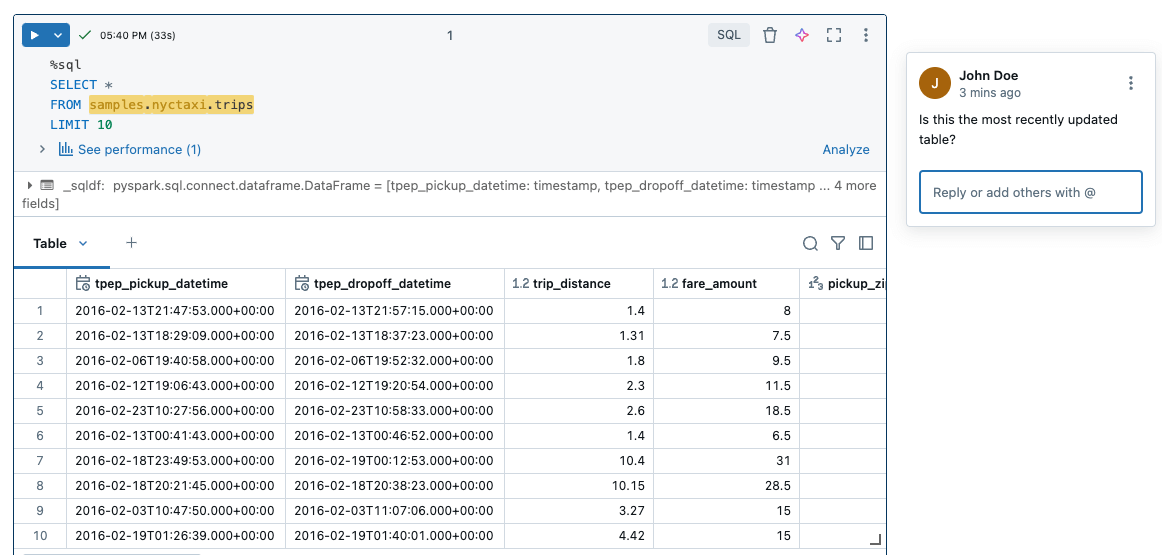
Work together to create and share projects in one place with the whole data team. Store markdown comments and code in multiple languages in Notebooks to share important context with others. See usage logs and forks on reports to understand how the analysis is being consumed.