7 Reasons to Migrate From Your Cloud-Based Hadoop to the Databricks Lakehouse Platform
by Chris Moon, Abhishek Dey and Ganesh Rajagopal
Over the past several years, many enterprises have migrated their legacy on-prem Hadoop workloads to cloud-based managed services like EMR, HDInsight, or DataProc. However, customers have started recognizing that the same challenges faced within their on-prem Hadoop environment (like reliability and scalability) get inherited into their existing cloud-based Hadoop platform. They observe that any cluster launch takes a long time to provision and even more time to autoscale during peak hours. As a result, they maintain long-running, overprovisioned clusters to manage the workload demands. A lot of time is spent on troubleshooting, infrastructure, resource management overhead and stitching different managed services on the cloud to maintain an end to end pipeline.
Finally, this leads to wasted resources, complicating security and governance and escalating unnecessary costs. Customers ultimately want their data teams to be able to focus on solving business challenges, rather than troubleshooting inherited Hadoop platform issues.
In this blog, we'll discuss the values and benefits of migrating from a cloud-based Hadoop platform to the Databricks Lakehouse Platform.
Here are some notable benefits and reasons to consider migration from those cloud-based Hadoop services to Databricks.
- Simplify your architecture with the Lakehouse Platform
- Centralized data governance and security
- Best-in-class performance for all data workloads
- Increased productivity gains and business value
- Driving innovation with data and AI
- A cloud agnostic platform
- Benefits of Databricks Partner ecosystem
Let's discuss in more detail and learn about these 7 reasons.
1) Simplify your architecture with the Lakehouse Platform
The Databricks Lakehouse Platform combines the best elements of data lakes and data warehouses to deliver the reliability, governance and performance of data warehouses with the openness, flexibility and machine learning support of data lakes.
Often, cloud-based Hadoop platforms are used for specific use cases like data engineering and need to be augmented with other services and products for streaming, BI, and data science use cases. This leads to a complicated architecture that creates data silos and isolated teams, posing security and governance challenges.
The Lakehouse Platform provides a unified approach that simplifies your data stack by eliminating these complexities.

2) Centralized data governance and security
Databricks brings fine-grained governance and security to lakehouse data with Unity Catalog. Unity Catalog allows organizations to manage fine-grained data permissions using standard ANSI SQL or a simple UI, enabling them to unlock their lakehouse for consumption safely. It works uniformly across clouds and data types.
Unity Catalog moves beyond just managing tables to other data assets, such as machine learning models and files. As a result, enterprises can simplify how they govern all their data and AI assets. It is a critical architectural tenet for enterprises and one of the key reasons customers migrate to Databricks instead of using a cloud-based Hadoop platform.
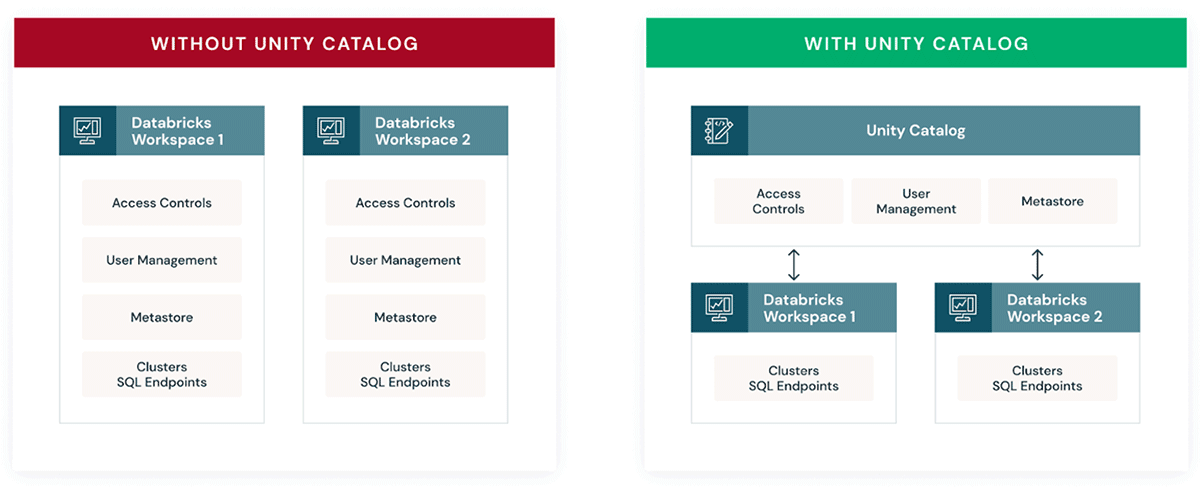
At a high level, Unity Catalog provides the following key capabilities:
- Centralized metadata and user management
- Centralized data access controls
- Data lineage
- Data access auditing
- Data search and discovery
- Secure data sharing with Delta Sharing
Apart from Unity Catalog, Databricks has features like Table Access Controls (TACLs), and IAM role credential passthrough which enable you to meet your data governance needs. For more details, visit the Data Governance documentation.
Additionally, with Delta Lake, you automatically reap the benefits of schema enforcement and schema evolution support out of the box.
Using Delta Sharing, you can securely share data across organizations in real time, independent of the platform on which the data resides. It is natively integrated into the Databricks Lakehouse Platform so you can centrally discover, manage and govern all of your shared data on one platform.
3) Best-in-class performance for all data workloads
Customers get best-in-class performance by migrating to the Databricks Photon engine, which provides high-speed query performance at a low cost for all types of workloads directly on top of the lakehouse.
- With Photon, most analytics workloads can meet or exceed data warehouse performance without moving data into a data warehouse.
- Photon is compatible with Apache Spark™ APIs and SQL, so getting started is as easy as turning it on.
- Written from the ground up in C++, Photon takes advantage of modern hardware for faster queries, providing better price/performance than other cloud data warehouses. For more details, please visit the blog post at data-warehousing-performance-record
Apart from this, Databricks Enhanced Autoscaling optimizes cluster utilization by automatically allocating cluster resources based upon workload volume, with minimal impact on the data processing latency of your pipelines. Cluster scaling is a significant concern with cloud-based Hadoop platforms, and in some cases, it takes up to 30 minutes to autoscale.
As a result of Databricks' superior performance compared to the cloud-based Hadoop platforms, the overall total cost of ownership dramatically decreases. Customers realize a reduced infrastructure spend and better price/performance simultaneously.
4) Increased productivity gains and business value
Customers can move faster, collaborate better and operate more efficiently when they migrate to Databricks.
- Databricks removes the technical barriers that limit collaboration among analysts, data scientists, and data engineers, enabling data teams to work together more efficiently. Customers see higher productivity among data scientists, data engineers and sql analysts eliminating manual overhead.
- Databricks' customers significantly accelerate time-to-value, and increase revenues by enabling data engineering, data science and BI teams to build end-to-end pipelines. On the other hand, they realized that it was impossible to achieve the same using a cloud-based Hadoop platform, where multiple services must be stitched together to deliver the needed data products.
With increased productivity, Databricks helps unlock new business use cases, accelerating and expanding value realization from business-oriented use cases.
A recent Forrester study titled The Total Economic Impact™ (TEI) of the Databricks Unified Data Analytics Platform found that organizations deploying Databricks realize nearly $29 million in total economic benefits and a return on investment of 417% over a three-year period. They also concluded that the Databricks platform pays for itself in less than six months.
5) Driving innovation with data and AI
Databricks is a comprehensive, unified platform that caters to all personas critical in delivering business value from data, like data engineers, data scientists & ML engineers, as well as SQL & BI analysts. Any member of your data team can quickly build an end-to-end data pipeline, starting with data ingestion, curation, feature engineering, model training, and validation to deployment within Databricks. On top of that, the data processing can be interchangeably implemented in both batch and streaming, utilizing the Lakehouse architecture.
Unlike cloud-based Hadoop platforms, Databricks constantly strives to innovate and provide its users with a modern data platform experience. Here are some of the notable platform features available to anyone using Databricks:
Lakehouse interoperability using Delta on any cloud storage
Delta Lake is an open format storage layer that delivers reliability, security and performance on your data lake — for both streaming and batch operations. By replacing data silos with a single home for structured, semi-structured and unstructured data, Delta Lake is the foundation of a cost-effective, highly scalable lakehouse. Compared to other alternative open format storage layers like Iceberg and Hudi, Delta Lake is the most performant and widely used format in the Lakehouse architecture.
ETL development using Delta Live Tables
Delta Live Tables (DLT) is the first ETL framework that uses a simple declarative approach to building reliable data pipelines and automatically managing your infrastructure at scale, so that data analysts and engineers can spend less time on tooling and focus on getting value from data. With DLT, engineers are able to treat their data as code and apply modern software engineering best practices like testing, error handling, monitoring and documentation to deploy reliable pipelines at scale.
Easy & automatic data ingestion with Auto Loader
One of the most common challenges is simply ingesting and processing data from cloud storage into your Lakehouse consistently and automatically. Databricks Auto Loader simplifies the data ingestion process by scaling automated data loading from cloud storages in streaming or batch mode.
Bring your warehouse to the data lake using Databricks SQL
Databricks SQL (DB SQL) allows customers to operate a multi-cloud lakehouse architecture within their data lake, and provides up to 12x better price/performance than traditional cloud data warehouses, open-source big data frameworks, or distributed query engines.
Managing the complete machine learning lifecycle with MLflow
MLflow, an open-source platform developed by Databricks, helps manage the complete machine learning lifecycle with enterprise reliability, security and scale. One immediately realizes the benefits of being able to perform experiment tracking, model management and model deployment with ease.
Automate your Machine Learning Lifecycle with AutoML
Databricks AutoML allows you to generate baseline machine learning models and notebooks quickly. ML experts can accelerate their workflow by fast-forwarding through the usual trial-and-error and focusing on customizations using their domain knowledge, and citizen data scientists can quickly achieve usable results with a low-code approach.
Build your Feature Store within the Lakehouse
Databricks provides data teams with the ability to create new features, explore and reuse existing ones, publish features to low-latency online stores, build training data sets and retrieve feature values for batch inference using Databricks Feature Store. It is a centralized repository of features. It enables feature sharing and discovery across your organization and also ensures that the same feature computation code is used for model training and inference.
Reliable orchestration with Workflows
Databricks Workflows is the fully-managed orchestration service for all your data, analytics, and AI needs. You can create and run reliable production workloads on any cloud while providing deep and centralized monitoring with simplicity for end-users. Workflows allow users to build ETL pipelines that are automatically managed, including ingestion, and lineage, using Delta Live Tables. You can also orchestrate any combination of Notebooks, SQL, Spark, ML models, and dbt as a Jobs workflow, including calls to other systems.
6) A cloud agnostic platform
A multi-cloud strategy is becoming essential for organizations that need an open platform to do unified data analytics, all the way from ingestion, to BI and AI.
- With data in multiple clouds, organizations can't afford to be constrained by one cloud's native services, since their existence now depends on the data residing on their cloud storage.
- Organizations need a multi-cloud platform that provides visibility, control, security and governance in a consistent manner for all their teams regardless of which clouds they are using.
- The Databricks Lakehouse Platform empowers customers to leverage multiple clouds through a unified data platform that uses open standards.
As a cloud-agnostic platform, Databricks workloads run similarly across any cloud platform while leveraging the existing data lake on each cloud storage. As a user, once you migrate the workloads to Databricks, you can use the same open source code interchangeably on any cloud. It mitigates the risks of locking you in a cloud-native Hadoop platform.
7) Benefits of Databricks Partner ecosystem
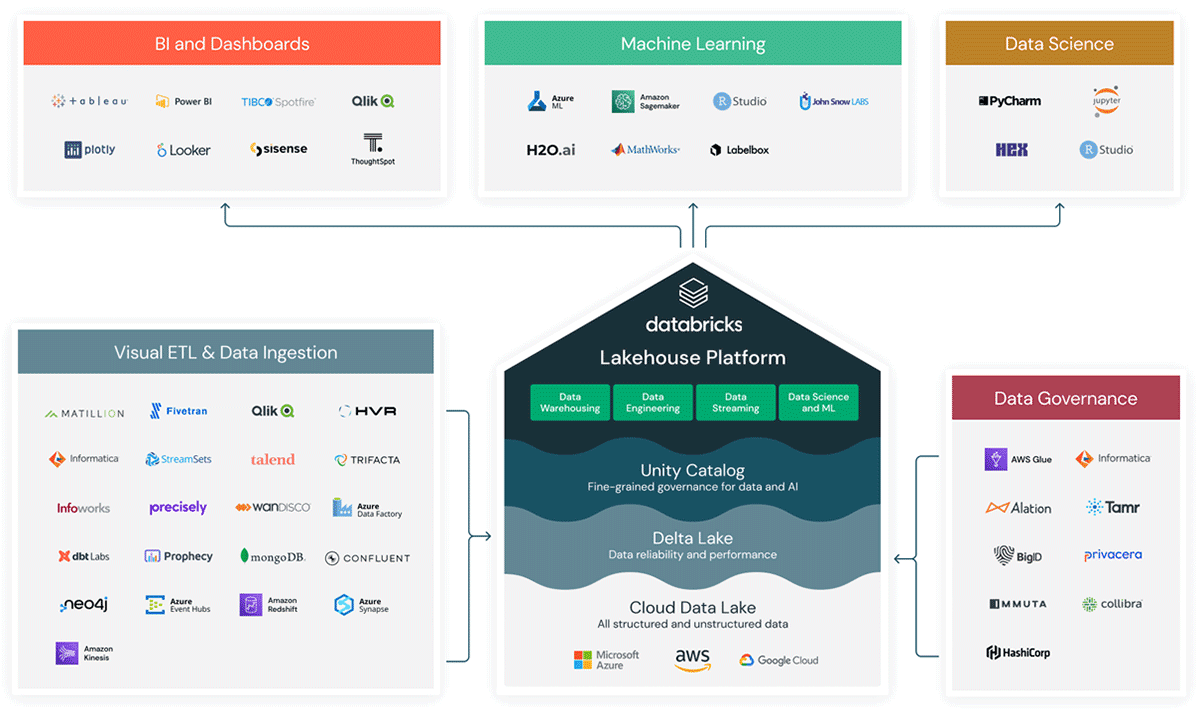
Databricks is an integral part of the modern data stack, enabling digital natives and enterprises to mobilize data assets for more informed decisions fast. It has a rich partner ecosystem (over 450 partners globally) that allows this to occur seamlessly across the various phases of a data journey, from data ingestion, building data pipelines, data governance, data science and machine learning to BI/Dashboards.
Within Databricks, Partner Connect allows you to integrate your lakehouse with popular data platforms like dbt, Fivetran, Tableau, Labelbox, etc. and set it up in a few clicks with pre-built integrations.
Unlike cloud-based Hadoop platforms, with Databricks, you can build your end to end pipeline with just a few clicks and rapidly expand the capabilities of your lakehouse. To find out more about Databricks technology partners, visit www.databricks.com/company/partners/technology.
Next Steps
Migration from one platform to another is not an easy decision to make. It involves
evaluating the current architecture, reviewing the challenges and pain points, and validating the suitability and sustainability of the new platform. However, organizations always look to do more with their data and stay competitive by empowering their data teams with innovative technologies to do more analytics and AI, while reducing infrastructure maintenance and administration burdens. To achieve these near and long-term goals, customers need a solution that goes beyond the legacy on-prem or cloud-based Hadoop solutions. Explore each of the 7 reasons in this blog and see how these can bring values to your business.

Migrating From Hadoop to Data Lakehouse for Dummies
Get faster insights at a lower cost when you migrate to the Lakehouse.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.