Creating Health Plan Price Transparency in Coverage With the Lakehouse
by Aaron Zavora, Brad Barker, Srijit Nair, Michael Sanky and Adam Crown
Check out our Price Transparency Solution Accelerator for more details, and to download the notebooks. Don't miss our Price Transparency On-Demand Webinar and complementary Workshop GitHub quickstart
What is price transparency and what challenges does it present?
In the United States, health care delivery systems and health plans alike are facing new regulatory requirements around price transparency. The Centers for Medicare and Medicaid Services (CMS) are responsible for enforcing these regulations, with an aim of increasing transparency and helping consumers better understand the costs associated with their healthcare.
Hospital price transparency first went into effect on January 1, 2021 and requires each hospital to provide clear, accessible pricing information online, both as a comprehensive machine-readable file with all items and services, and as a display of shoppable services in a consumer friendly format.1 In practice, major shortcomings like total costs for hospital services being misrepresented and ambiguous requirements on data format, meaning, and availability serve as barriers to consumers.
Health plan price transparency (also known as Transparency in Coverage), first went into effect on July 1, 2022, and requires health plans to post information for covered items and services. The regulations are intended, at least in part, to enhance consumers' ability to shop for the health care that best meets their needs.2
Organizations are facing challenges with this mandate both in sharing data per the regulations and consuming data for comparison purposes. Some basic challenges for payers posting data include ambiguity around CMS requirements, the need to bring disparate datasets across an organization (plan sponsors, provider networks, rate negotiation), and the sheer volume of data being produced by an organization. Equal challenges for consuming by customers are prevalent as well: working with large volumes of data, consuming semi-structured data formats, and conforming datasets through curation and analytics.
What role does Databricks play?
Databricks is a platform built for scalability upon open source standards. This applies to the vast amount of data being produced and the semi-structured nature of CMS price transparency format. Leveraging the platform's open standards, we can extend functionality and seamlessly build solutions that not long ago seemed implausible.
Closing the gap for analytics:
A Custom Apache Spark™ Streaming Approach
Stated simply, we want to be able to read large Price Transparency Machine Readable File (MRF) data natively in Apache Spark (core to scalable distributed processing capability), and start using SQL (arguably the best capability for widespread analysis) for comparing rates. Our approach below will ultimately produce the result:
To understand the challenge for performing analysis on this data provided, we need to know a little more about how this data is being provided. CMS does provide basic guidelines3 for the data to conform to, and for the most part, health plans have been posting the information in JSON format which is a type of key/value structure.
The challenge presents itself because of a combination of two factors: the first is that these MRFs can be very large. A 4GB zipped file may unzip to 150GB. This alone does not present an insurmountable challenge. The compounding factor that makes size relevant is that the JSON structure mandated by CMS allows for the creation of just one JSON object. Up until now, many JSON parsers work by reading the entire JSON object. Even the fastest parsers like simdjson (a GPU JSON parser) require the entire object to fit neatly into memory. Hence we look for another solution.
Our approach is to stream the JSON object and parse on the fly. This way, we avoid the need to fit the entire object into memory and there are several JSON parsers out there that do just this. However, this approach still does not deliver a consumable structure for analytics. Turning a 150GB JSON file into 500 small JSON files on a local machine still leaves a lot to be desired.
Here is where we see Spark Structured Streaming having a distinct advantage. First, it is fully integrated with the high performance and distributed capabilities of Spark itself. Secondly, it has manageable restart capabilities, saving and committing offsets so that a process can restart gracefully. Third, one of the most efficient ways to perform analysis is using Databricks SQL (DBSQL). Spark Streaming allows us to land these large JSON objects in a way that we can immediately start leveraging DBSQL. No further heavy transformations. No major data engineering or software engineering skills needed.
So how does it work? First, we need to understand Spark's Structured Streaming contracts. Once we understand Spark's expectations, we can then develop an approach to split both large JSON files and many JSON files at scale.
Implementing a custom Spark Streaming source
Note: For the data engineer, software engineer, or those that are curious, we will deep dive into some Spark internals with Scala in this section.
What is it?
In order to be a custom spark streaming we must implement two classes, StreamSourceProvider and Source. The first tells Spark the provider of the custom source. The second describes how Spark interacts with the customer source. We'll focus on the latter in this article as it provides the bulk of our implementation.
Let's look briefly at what it means to extend source:
Without going into too much detail, we can tell that Spark will do a few important things:.
- Spark wants to know the schema resulting from our custom source
- Spark will want to know what "offset" is currently available from the stream (more on this later)
- Spark will ask for data through start/end offsets via getBatch() method. We will be responsible for providing the DataFrame (actually an execution plan to produce a DataFrame) represented by these offsets
- Spark will periodically "commit" these offsets to the platform (meaning we do not need to maintain this information going forward)
A JSON file streaming source
Thinking about this within the context of our objective to split massive JSON files, we want to provide subsets of the JSON file for Spark. We'll split the responsibility of "providing" offsets and "consuming" offsets into separate threads and provide synchronous access to a shared data structure between threads.
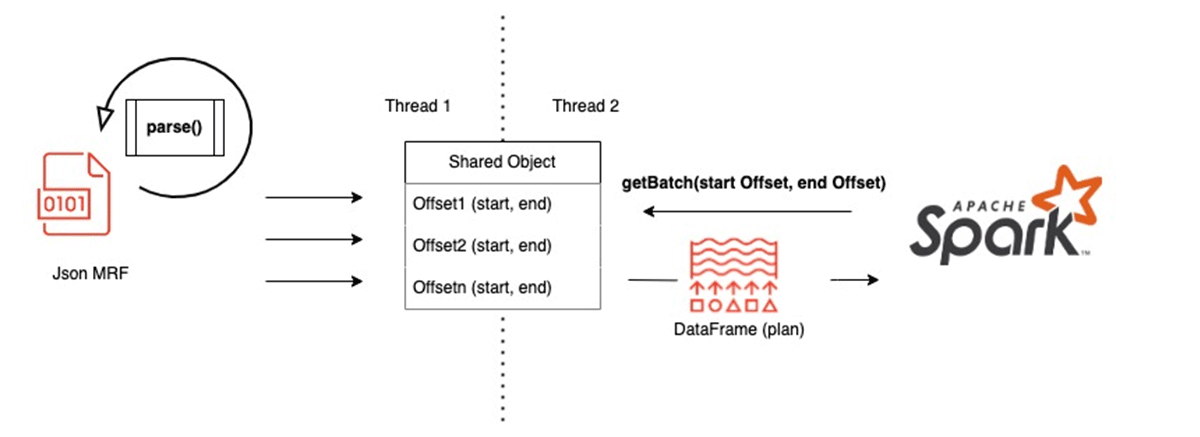
Because this shared data structure is mutable, we want to make this as lightweight as possible. Simply, we can provide a lightweight representation of a subset of a JSON file as start and end locations. The purpose of "headerKey" is to represent the JSON key for a large list that may be split (in case we are in the middle of this list and splitting it). This will provide more readability into our resulting JSON splits.
This data structure will hold a single "offset" that spark will consume. Note this representation is multi purpose as a way to represent a row(s) and partition(s) in our data.
Materializing Offsets in Spark
The JsonPartition case class above provides an offset of our JSON file in the stream. In order to make use of this information we need to tell Spark how to interpret this to produce an internal row.
This is where the compute method comes in. This method in our class has information regarding (1) the JsonPartition with file start/end offsets and the headerKey string as well as (2) the fileName that we are parsing from the class instantiation.
Given this information, it is fairly straightforward to create a Row in the compute function. Loosely it looks something like this:
Bringing this full circle, we implement our getBatch() method by:
(1) Filtering for the JsonPartition sequence Spark requested in the start/end offsets
(2) FInally creating a new compute() plan for Spark to interpret into a DataFrame
JSON parsing
As it relates to Spark Streaming
As for the JSON parsing, this is a little more straightforward. We approach this problem by creating the class ByteParser.scala which is responsible for iterating through an Array (buffer) of bytes to find important information like "find the next array element" or "skip white spaces and commas".
There is a separation of duties among the program where ByteParse.scala serves as purely functional methods that provide reusability and avoid mutability and global state.
The caller program is the Thread created in JsonMRFSource and is responsible to continually read the file, find logical start and end points in an array buffer while handling edge cases, and has the side effect of passing this information to Spark.
How do you split a JSON file functionally?
We start with the premise of representing data in a splittable format without losing any meaning from the original structure. The trivial case being that a key/value pair can be split and unioned without losing meaning.

The nontrivial case is data from the "in_network" and "provider_referencs" key often contains the bulk of information for MRF. Therefore it is not sufficient to just split on key/value pairs. Noting that each of these keys has an array value data structure, we split the arrays further.
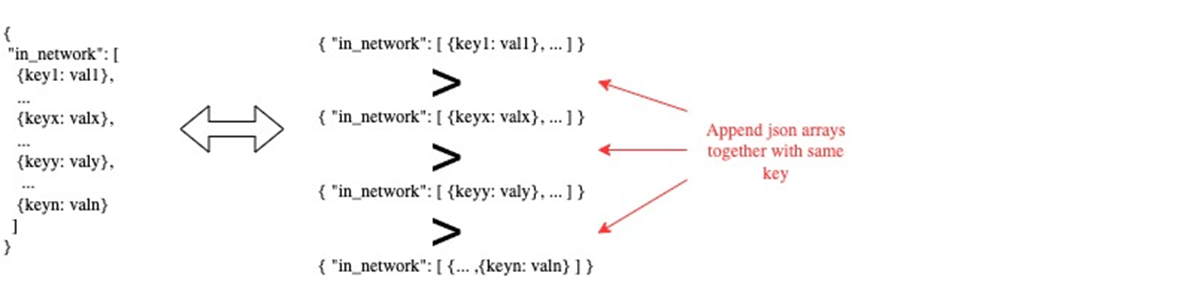
With this split approach our resulting dataset from the custom readStream source contains 3 fields of output: file_name, header_key, and json_payload. Column file_name persists information needed from the trivial case and header_key persisting information needed from the nontrivial case.
e.g. ,

Meeting the 2023/2024 CMS reporting mandates with DBSQL
An example of how to use the custom streamer is found in a demo notebook where we download, parse, and run some simple SQL commands that split the nested JSON data into separate tables.
The final query of the demo takes a provider practice and procedure code as parameters and provides a simple comparison of price between all the physicians at the practice. Some sample next steps in making the result consumer friendly could be listing out provider names and specialties by combining public data from NPPES, create a procedure selection list from searching keywords in the description, and overlaying with a UI tool (RShiny, Tableau, etc).
The value of transparency
The vision for CMS's price transparency mandate is to benefit consumers through a transparent and holistic view of their healthcare shopping experience prior to stepping foot into a provider's office. However, the obstacles to achieving this objective go beyond harnessing the MRF data published at scale.
Healthcare coding is extremely complex and the average consumer is far away from being able to discern this information without a highly curated experience. For a given provider visit, there can be dozens of codings billed, along with modifiers, as well as considerations for things like unexpected complications that occur. All this to say that accurately interpreting a price remains a challenge for most consumers.
To compound the interpretation of price, there likely are situations in healthcare where a trade-off in price corresponds to a trade-off in quality. While quality is not addressed in price transparency, there are other tools such as Medicare STARS ratings that help to quantify a quality rating.
One certain effect of the regulations is more visibility into the competitive dynamics in the market. Health plans now have access to critical competitive insights previously unavailable, namely the provider network and negotiated prices. This is expected to impact network configurations and rate negotiations, and in all likelihood, will reduce price outliers.
Producing value from transparency requires analytical tooling and scalable data processing. Being a platform built on open standards and highly performant processing, Databricks is uniquely suited to helping healthcare organizations solve problems in an ever more complex environment.
1 https://www.cms.gov/hospital-price-transparency
2 https://www.cms.gov/healthplan-price-transparency
3 https://github.com/CMSgov/price-transparency-guide/tree/master/schemas
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.