The 3Ds of Migrating Teradata Workloads to Databricks
Best practices for migrating Teradata workloads to Databricks
by Suresh Matlapudi, Mendelsohn Neil Chan , Abhishek Dey and Soham Bhatt
- Discover, develop, and deploy for systematically migrating Teradata workloads to the Databricks lakehouse architecture.
- Use scalable utilities like Teradata Parallel Transporter (TPT) and automated code conversion tools.
- Use Databricks Workflows to orchestrate anything anywhere, including any combination of notebooks, SQL, Spark, ML models, and more.
Many large enterprises have used Teradata data warehouses for years, but the storage and processing costs of on-premises infrastructure severely restricted who could use the resource and for what purposes. On top of that, an upgrade is a long process, plus Teradata needs to ship the customers the hardware and install it in the customer's data center in the event of an outage.
Migrating your legacy Teradata data warehouse to the Databricks Data Intelligence Platform can accelerate your data modernization journey. Still, it may seem complex and daunting, requiring a well-orchestrated and planned effort. During the initial scoping phase, you may discover that your organization has accumulated hundreds of jobs and thousands of SQL scripts over the years.
However, fear not! Enterprise customers like Walgreens, Sam's Club and many others have successfully migrated their legacy Teradata Data Warehouse to Databricks, enabling them to save millions in infrastructure savings while at the same time accelerating innovation and productivity. This blog post presents a systematic strategy to accelerate your journey toward adopting the lakehouse in a framework encapsulated in an acronym, 3Ds: Discovery, Development, and Deployment.
If you are wondering how Databricks is different from Teradata, the summary matrix below illustrates how the Databricks Lakehouse Platform compares to a traditional data warehouse like Teradata:
Capabilities comparison
| Databricks | On-Premises Teradata | |
|---|---|---|
| Data format | Delta (open source) | Proprietary |
| Data types | Structured, Semi-structured, Unstructured | Structured, Semi-structured |
| Languages supported | SQL, Python, Scala, R | SQL only |
| Use cases | BI, SQL, Machine Learning/ Data Science, Real-Time Streaming | BI, SQL |
| Reliability | High-quality, reliable data with ACID transactions | High-quality, reliable data with ACID transactions |
| Governance | Fine-grained access control for tables, rows, columns with Unity Catalog | Fine-grained access control for tables, rows, columns |
| Architectural paradigm | Lakehouse Platform | Traditional Data Warehouse |
| Licensing Model | Consumption based | Annual subscription + Additional feature(s) + Support/ Maintenance + Upgrades cost |
Step 1: Discovery
Profile the Teradata Environment
The first step in the migration process is to comprehensively understand your Teradata environment to determine the overall scope and effort required for the initiative. Below are two key questions you'd want to know about your Teradata deployment:
Question #1: What does my Teradata topology look like regarding hardware specs? (e.g., storage utilization, system utilization, warehouse objects information, query types)
To answer this question, extracting and analyzing syslogs from your Teradata warehouse environment is a great place to start. To accelerate this process the Databricks migrations team has developed a Teradata Profiler tool to accelerate this process. The profiler uses Teradata's system tables and service called PDCR (Performance Data Collection and Reporting), a data application that provides an understanding of system performance, workload utilization, and management. This migration assessment utility helps you automatically discover and profile the current Teradata Warehouse environment. In addition, the tool also helps in DBU (Databricks Unit) forecasting. The screenshot below illustrates the key insights generated by the Teradata Profiler dashboard (for more information on running the profiler, please get in touch with your Databricks representative):
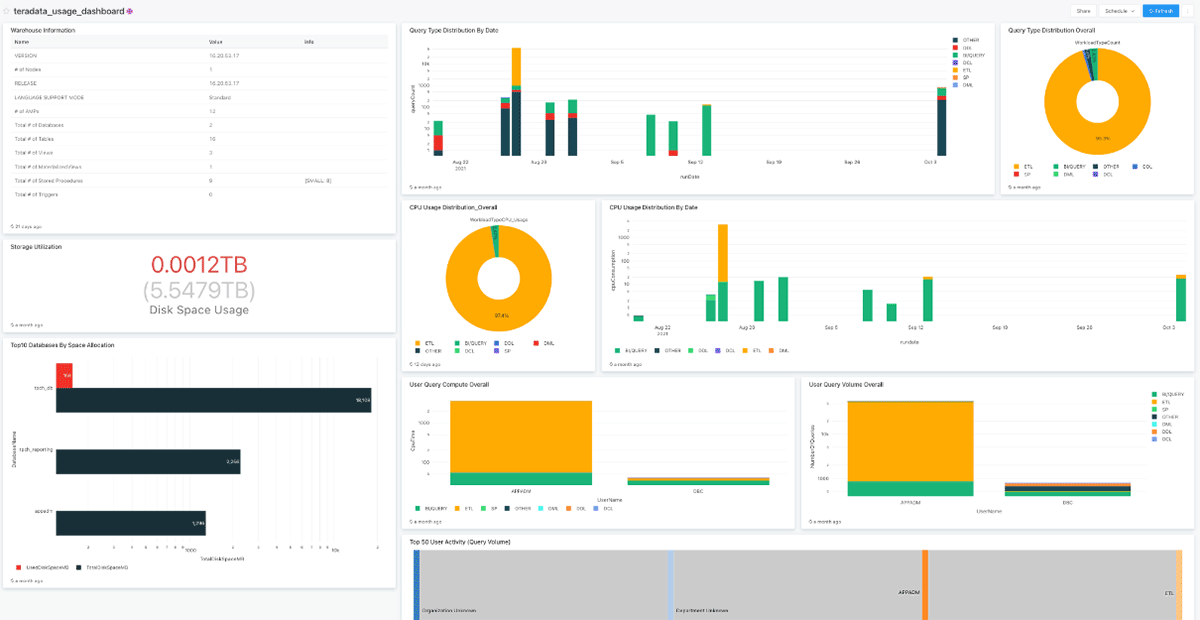
Question #2: How many workloads do I need to migrate to Databricks? How easy or complex are my environment's jobs and code patterns?
To answer this second question, you need to review the actual code, scripts, data warehouse objects, and jobs accumulated in your Teradata warehouse environment and create a summary inventory of these artifacts. To accelerate this analysis process, Databricks highly recommends utilizing a code profiler or analyzer (e.g., BladeBridge, LeapLogic, DataMetica etc.) or solution accelerators built by one of our BrickBuilder Migration Solution partners. These tools typically provide detailed reports of what's inside your environment and break down data pipelines and jobs into various buckets based on complexity. It allows you to scope out the effort required for the migration initiative and any code refactoring that may be necessary during this process.
In addition to analyzing jobs complexity, these analyzer tools produce several useful summaries, including a listed inventory of assets and artifacts in the Teradata environment; examples include
- SQL scripts
- Dynamic SQL
- Functions,
- Referenced Objects
- Program-Object Cross Reference
- Total Lines of Code
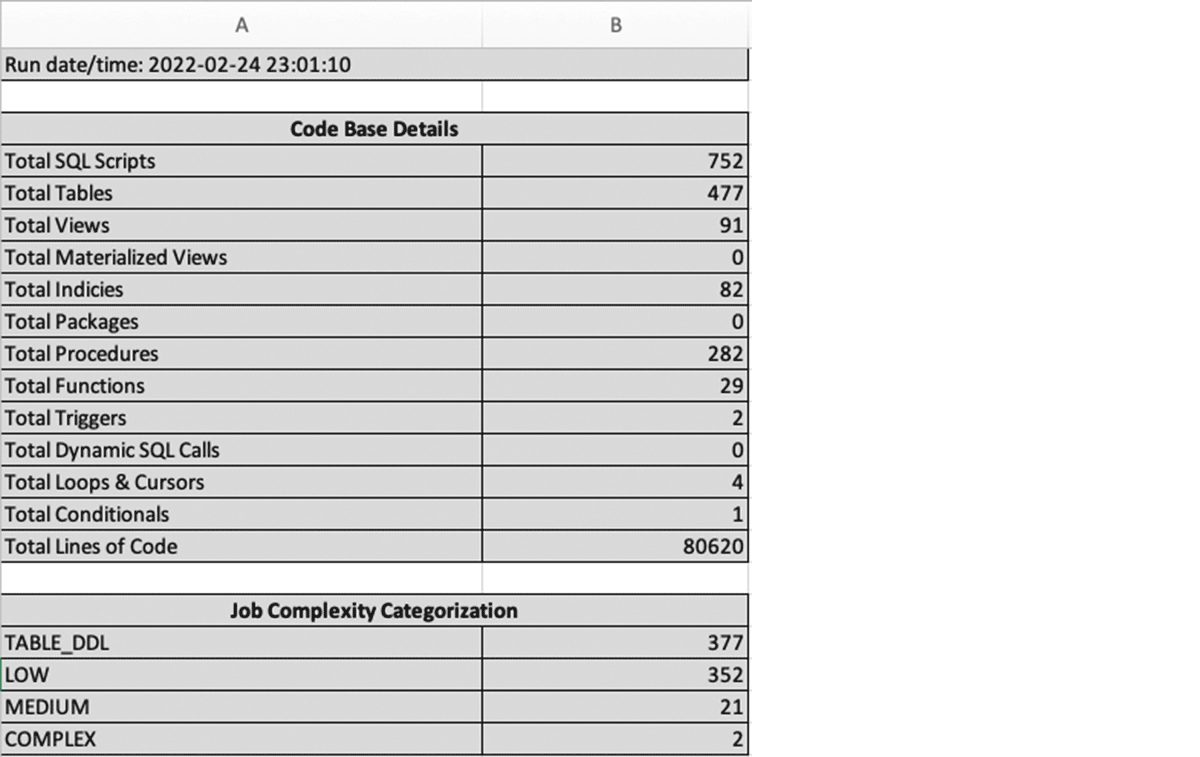
The analyzer provides a good understanding of your Teradata warehouse environment by auto-analyzing the code/scripts, as you can do a detailed migration assessment and effort estimation. You are ready to embark on the next step in your migration journey!
Step 2: Development
Now that you have assessed your Teradata workloads in the discovery step, the next step is the actual migration of historical data and associated workloads to the Databricks lakehouse architecture. This section will walk you through the development activities to achieve that.
2.1 Data Warehouse Extraction
To get started with data migration, the Teradata Parallel Transporter (TPT) is a client utility that provides scalable, high-speed, and parallel data extraction and loading. Using TPT, you can extract the data from all your tables in Teradata at scale and then push the data files into cloud object stores such as AWS S3, Azure Data Lake Storage, or Google Cloud Storage. Utilizing TPT to unload data offers several critical benefits listed below:
- Ability to define field delimiter, date formats, and encoding type
- Control to determine resource allocation for data unloading to achieve better performance
- Define the number of generated output files and their corresponding file type
- Supports checkpointing and resume operations in case of failures and interruptions
Alternatively, you can use a CDC Ingestion tool of your choice, provided by our Ingestion Partners, to perform the above operation as well. You can push these extracted files to the cloud storage using cloud-native CLI or managed services or use any open source/third-party ingestion tools.
Once the extracted load-ready files in csv or text formats have landed on the cloud storage, you can use Databricks Autoloader for automatic incremental ingestion. It will take care of the historical data ingestion.
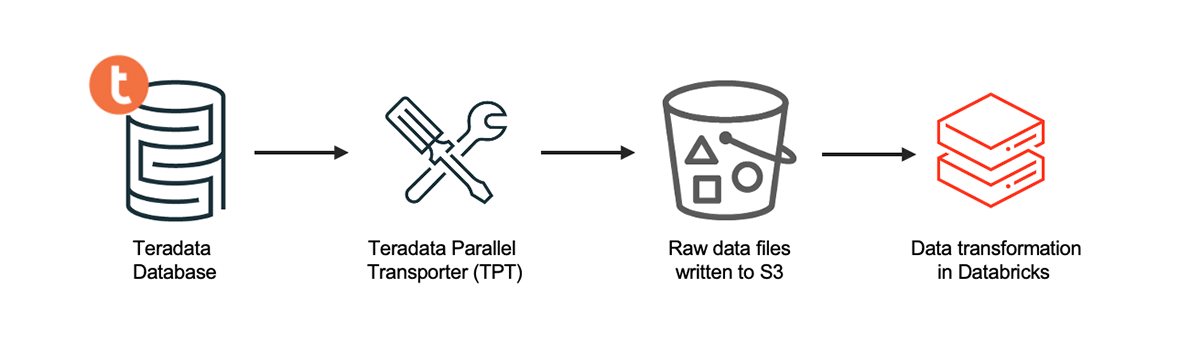
From an incremental load standpoint, you must ensure that the ingestion process pushes the source data to the cloud storage location for all the tables in scope. We recommend using the original source systems directly to decouple the ingestion pipeline and remove dependency on Teradata as a source system. Usually, this is a CDC source, which is handled by ingestion tools like Fivetran (HVR), Airbyte, Debezium, Azure Data Factory, AWS DMS, Arcion or others, depending on your choice of ingestion tooling and source system(s). In the case of existing logic using MLoad, TPT or Fast Load scripts, where you are performing incremental loads into Teradata today, that can be taken care of as part of MERGE INTO functionality in Databricks.
2.2 Code conversion and pipeline development
When converting code from your Teradata Warehouse environment to Databricks, the primary goal is to leverage automated methods as much as possible. The conversion of the Teradata logic and functionality using one of our migration tooling ISV partners or a BrickBuilder solution simplifies and accelerates the modernization effort to a large extent. As a best practice for migration, we recommend that you group related code belonging to a data application end-to-end or subject area together and trace it backwards from the reporting layer to the base tables.
Migrating code that has accumulated over the years may seem to be an intimidating and daunting task. Let's break them down into four major categories listed below and explore each area in more detail to approach the code migration systematically:
- Data Type Conversion
- Table DDLs
- Table DMLs
- BTEQ Scripts
- Stored Procedures
Teradata has its dialect of the SQL language but conforms closely to the ANSI SQL that Databricks adheres to. Below are the indicative guidelines for code conversion between Teradata and Databricks:
1. Data Type conversion
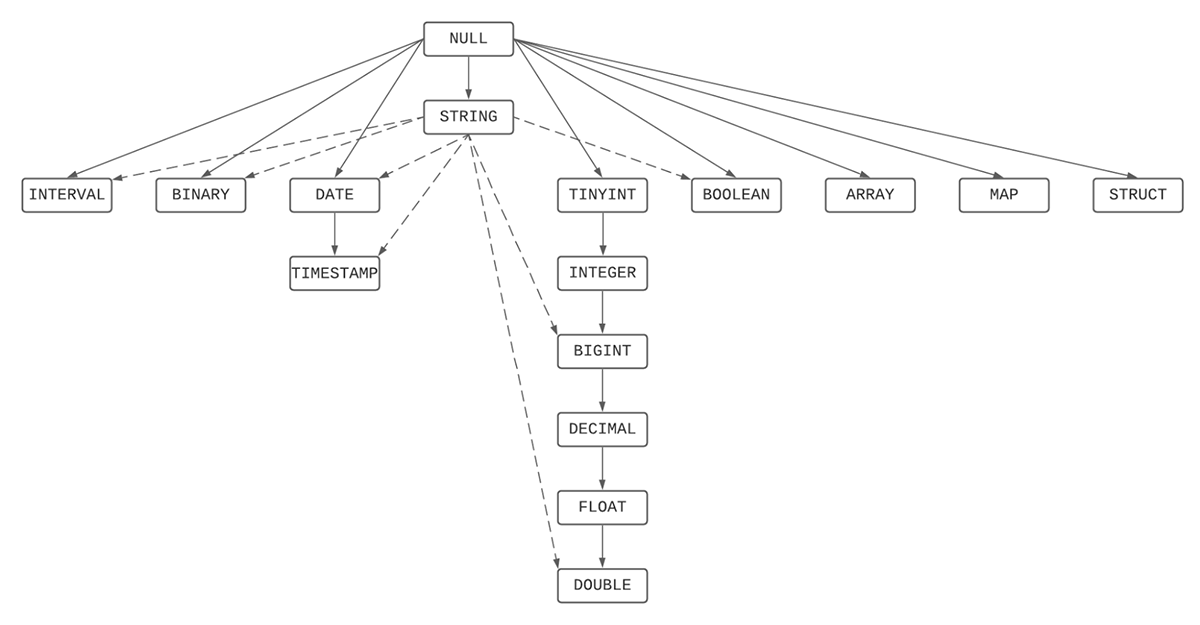
The conversion of SQL data types from Teradata to Databricks is straightforward, due to the ANSI-compliance of Databricks SQL. DDL statements and scripts in Teradata can be ported over to Databricks seamlessly, with most source data types being retained.
On certain occasions, the process of type promotion will occur, which is the process of casting a type into another type of the same type family which contains all possible values of the original type. To illustrate with an example, TINYINT has a range from -128 to 127, and all its possible values can be safely promoted to INTEGER. For a full list of supported SQL data types in Databricks and their type precedence during the conversion process, kindly refer to the link here and our release notes.
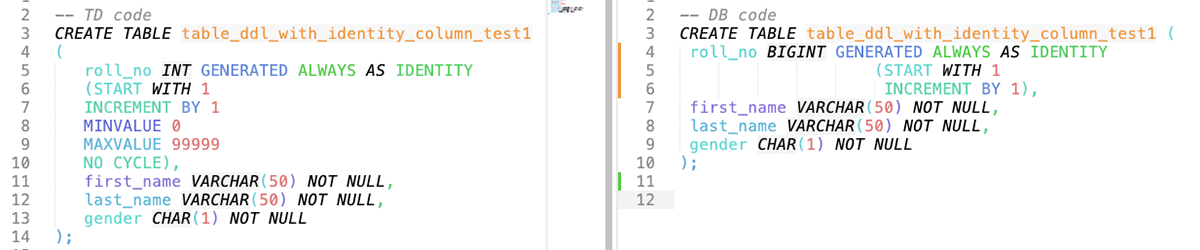
2. Table DDLs using Identity Columns
Identity Columns are now GA (Generally Available) in Databricks Runtime 10.4 and beyond. Through identity columns, you can now enable all your data warehousing workloads to have all the benefits of a lakehouse architecture.
3. Table DMLs and Function Substitutions
Databricks SQL (DBSQL) supports many standard SQL functions; hence the most commonly used SQL functions in Teradata are also interoperable with DBSQL code without required refactoring. Any Teradata functions not supported in native DBSQL can be handled using User-Defined Functions (UDFs). This link contains an alphabetically ordered list of built-in functions and operators in Databricks.
4. BTEQ Scripts
If you have BTEQ scripts, you must convert them into SQL-based logic wrapped in Python and import them into your Databricks workspace environment as notebooks. A quick summary of the top 5 most common BTEQ functionality, commands and their equivalent converted state in Databricks is shown below:
| # | Teradata BTEQ Command | Databricks Equivalent |
|---|---|---|
| 1 | IMPORT | COPY INTO |
| 2 | EXPORT | INSERT OVERWRITE DIRECTORY |
| 3 | RUN | dbutils.notebook.run |
| 4 | IF THEN | Python if block |
| 5 | IF, ELSEIF, ELSE, ENDIF | Python if…elif…else block |
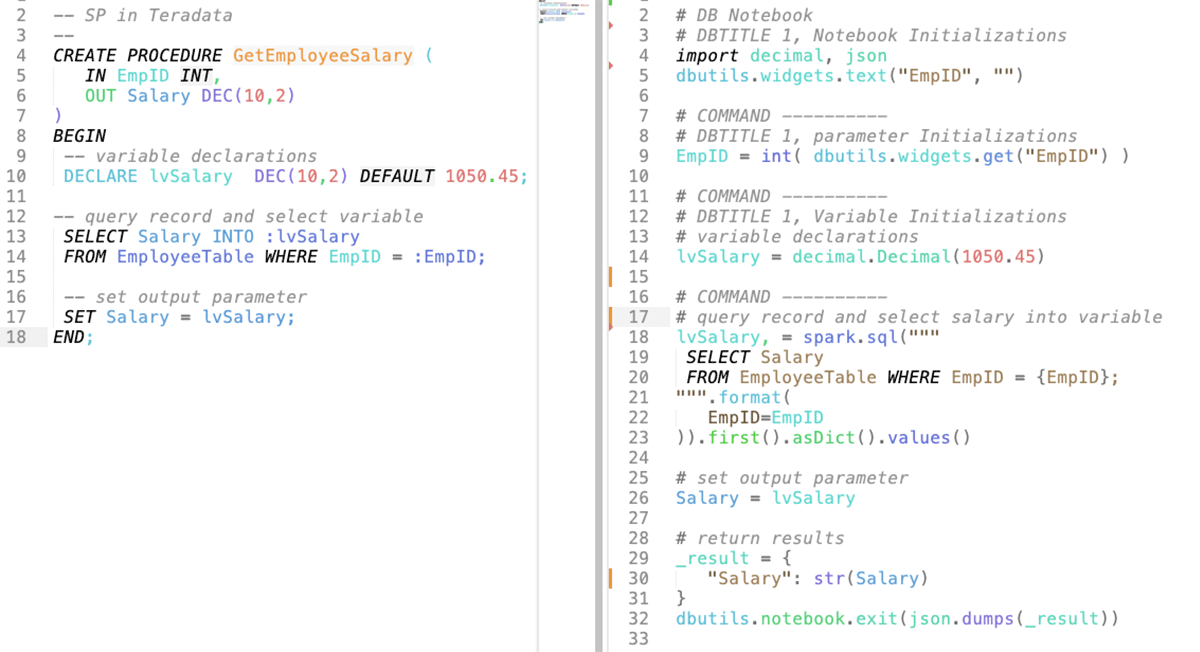
5. Stored Procedures
Teradata stored procedures can be easily migrated to Databricks using the newly supported SQL scripting that provides stored procedure functionality within Databricks. Databricks PySpark Notebooks and Workflows can also be used to modularize and orchestrate the stored procedure steps. The recommended approach is leveraging the automated code conversion tools mentioned above to accelerate this process. Following is a high-level summary of how most auto conversion tools handle Teradata Stored Procedures and its equivalent functionality in Databricks.
- CREATE Stored Procedure statements from the input code are converted to Databricks notebooks using Python and SQL in the output
- Each Stored Procedure maps to an equivalent Databricks notebook.
- CALL Stored Procedure statements to equivalent dbutils.notebook.run calls with appropriate parameter serialization and return value deserialization
The tabular matrix below summarizes specific Stored Procedure functionality in Teradata and how to migrate its features into Databricks:
| # | Teradata Stored Procedure Construct |
Migration Process / Equivalent Component in Databricks |
|---|---|---|
| 1 | SQL Statements | Stored Procedures contain SQL statements that undergo the same conversion rules to Databricks as described in this blog's SQL conversion section |
| 2 | Parameters | Parameters are converted to output Python notebook parameters through Databricks' widgets functionality. Data type conversion from Teradata SQL types to Python types is taken care of in the conversion process |
| 3 | Variable declarations | Converted to Python variables with appropriate data type conversions |
| 4 | IF THEN | Converted to Python if block |
| 5 | IF, ELSEIF, ELSE, and ENDIF | Converted to Python if…elif..else block |
| 6 | CASE | Converted to Python if…elif..else block |
| 7 | CALL statements | Stored Procedure CALL statements are converted to dbutils.notebook.run calls with appropriate parameter serialization and return value deserialization. You can also share the context between different tasks using task values, if you want to break a large piece of code logically and leverage Databricks workflows effectively. |
2.3 Data modeling
Apart from the code, if you are worried about migrating your custom data model on Teradata, Databricks supports all data modeling paradigms. You can use that as-is on the lakehouse. Data Modelers and architects can quickly re-engineer or reconstruct databases and their underlying tables or views on Databricks. You could leverage tools like erwin Data Modeler with the Databricks lakehouse architecture to serve these needs and reverse engineer using the existing model to fast-track migration to Databricks. We recommend that you follow our blogs for data modeling best practices.
Step 3: Deployment
Now that you have converted your core Teradata logic into Databricks equivalent, you are ready for deployment. There are several best practices of which you should be aware.
3.1 Workspace setup
When designing your workspace, there are various options to set up logical boundaries based on your existing data model, governance model and enterprise architectural design decisions:
- Three workspace approaches based on environments - e.g., dev, stage and prod. In addition, we expect it to align with the logical separation of the corresponding schemas for the data.
- Isolation by the line of business ( LOB ), and one would have LOB-based dev, stage and prod workspaces within each LOB. You could also have sub-LOBs within each LOB and, within that, different value streams or projects isolate the ownership. This could be aligned with the cloud account setup as well. This strategy works well with enterprises bound by privacy and regulatory requirements.
- Create separate workspaces for each team that owns the data. This, in turn, allows each team to control the data it produces and helps ensure data ownership is evident. It works well for enterprises that want to implement data mesh architecture.
For more information, we recommend you follow these best practices on workspace setup.
Once the workspaces are set up, you can test your migrated workloads and deploy them into production. For CI/CD, you can use Databricks Repos and the best practices around it.
We typically help you perform a Total Cost of Ownership (TCO) analysis and consumption planning for the required Databricks Units (DBUs) to support these workloads from a budgeting standpoint. Please contact your Databricks representative for this exercise.
3.2 Orchestration using Workflows
Traditionally, Teradata workloads are orchestrated using schedulers like Control-M, Autosys or similar tools with Unix-based wrapper scripts. Enterprises also embed the ELT logic as part of the enterprise ETL components, which push down the SQL logic on execution.
With Databricks, you can use Workflows out of the box and orchestrate anything anywhere. Workflows are free of cost, and you can orchestrate any combination of notebooks, SQL, Spark, ML models, etc., as a Jobs workflow, including calls to other systems. These Workflows can be scheduled using Databricks scheduler.
As part of the migration activity, you can modernize your Teradata workloads to Databricks and eliminate licensed scheduling tools to adopt the modern data stack as an option entirely. For example, if you have converted your BTEQ scripts into notebooks, you can now orchestrate them as Tasks using Workflows with the required dependencies for deploying the end-to-end pipeline.
3.3 Data validation and user acceptance testing
To deploy workloads successfully into production, you will need to plan for data validation by the end users/business analysts' teams. The business analysts' teams use row counts and summaries of key attributes or metrics of the tables in scope and compare them by running their SQL models on Teradata and Databricks. We recommend that you keep an overlapping window between the two systems for validations side by side. Once the teams sign off with the completion of User Acceptance Testing (UAT), you can plan for a cutover for all the related workloads. Usually, these capabilities are a subset of the BrickBuilder solutions or migration tooling ISV partners and can be easily automated for ease of use and accelerated journey.
Another critical factor during user acceptance testing is meeting the performance SLAs. You will get best-in-class performance by migrating to Databricks with a much lower TCO, as it uses a Photon engine providing high-speed query performance at a low cost for all types of workloads directly on top of the lakehouse.
For more details, please visit this blog post on data-warehousing-performance-record.
To ensure you get the best performance, we recommend you follow the delta optimizations best practices.
3.4 Data governance strategy
Databricks brings fine-grained governance and security to lakehouse data with Unity Catalog. Unity Catalog allows organizations to manage fine-grained data permissions using standard ANSI SQL or a simple UI, enabling them to unlock their lakehouse for consumption safely. It works uniformly across clouds and data types.
Unity Catalog moves beyond managing tables to other data assets, such as machine learning models and files. As a result, enterprises can simplify how they govern all their data and AI assets. It is a critical architectural tenet for enterprises and one of the key reasons customers migrate to Databricks instead of using a traditional data warehousing platform.
In this case, you can easily migrate over the Teradata-based access controls to Databricks using Unity Catalog.
3.5 Repointing BI workloads
One of the critical requirements of a successful Teradata to Databricks migration is ensuring business continuity, enabling adoption and alleviating any downstream impacts. Databricks has validated integrations with your favorite BI tools, including Databricks Dashboards, Power BI, Tableau, Redash, Preset, AWS Quicksight, Looker and others, allowing you to work with data through Databricks SQL warehouses. The general norm for a given set of reports for a given KPI is to ensure all the upstream tables and views are migrated, along with their associated workloads and dependencies.
Assuming the metadata is migrated to Unity Catalog, we could the following approach for seamless repointing of reports, as applicable. Let us assume that the new tables or views under UAT have the suffix _delta. Once the tables/views in scope with UAT are completed, and associated pipelines are migrated, you should rename the existing Teradata tables/views with the suffix ( e.g., _td) and rename the new tables/views (e.g., _delta) to the current table or view names. This approach ensures that end users do not have to refactor the table or view names within the SQL models or reports, and existing reports can be migrated using your automated solution with minimal syntax changes. Note: You could follow an approach with separate database/schema names maintained for the lakehouse, as dictated by your data strategy team as well.
Once you have migrated the 1st set of KPI dashboards or reports, you can now iterate through the remainder of the reporting layer and its migration.
Practical tips from Accenture
Accenture shared some practical tips for migrating from Teradata to Databricks in this webinar. Check it out to hear about how the migration worked at a utilities company! Highlights include:
- A Teradata migration is not just a database migration.
- Discovery is crucial to a high-confidence plan.
- Engage all of the stakeholders.
- Don't migrate what you don't need.
- Don't forget about history.
Summary
A seamless migration is an important step to ensure the success of your business outcomes. In the above blog sections, we walked you through the important aspects of completing your migration journey.
Next steps
Many enterprises today are running a hybrid architecture — data warehouses for business analytics and data lakes for machine learning. But with the advent of the data lakehouse, you can now unify both on a single modern platform. The Databricks lakehouse architecture overcomes traditional MPP data warehouse limitations because it is designed to manage all types of data - structured, semi-structured, and unstructured - and supports traditional BI workloads and Machine Learning / AI natively. It adds all this functionality to your data lake, creating a unified, single, and multicloud platform.
Migrating your Teradata environment to Databricks delivers significant business benefits, including
- Reduction of operational costs,
- Increased productivity of your data teams,
- Unlocking advanced analytics use cases while retaining full data warehouse capabilities.
Migration can be challenging. There will always be tradeoffs to balance and unexpected issues and delays to manage. You need proven partners and solutions for the migration's people, process, and technology aspects. We recommend trusting the experts at Databricks Professional Services and our certified migration partners, who have extensive experience delivering high-quality migration solutions promptly. Reach out to get your migration assessment started.
We also have a complete Teradata Server to Databricks Migration Guide–get your free copy here.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.