Simplify PySpark testing with DataFrame equality functions
Introducing PySpark DataFrame equality test functions, why they matter, and how to use them.
by Haejoon Lee, Allison Wang and Amanda Liu
The DataFrame equality test functions were introduced in Apache Spark™ 3.5 and Databricks Runtime 14.2 to simplify PySpark unit testing. The full set of capabilities described in this blog post will be available starting with the upcoming Apache Spark 4.0 and Databricks Runtime 14.3.
Write more confident DataFrame transformations with DataFrame equality test functions
Working with data in PySpark involves applying transformations, aggregations, and manipulations to DataFrames. As transformations accumulate, how can you be confident that your code works as expected? PySpark equality test utility functions provide an efficient and effective way to check your data against expected outcomes, helping you identify unexpected differences and catch errors early in the analysis process. What's more, they return intuitive information pinpointing precisely the differences so you can take action immediately without spending a lot of time debugging.
Using DataFrame equality test functions
Two equality test functions for PySpark DataFrames were introduced in Apache Spark 3.5: assertDataFrameEqual and assertSchemaEqual. Let's take a look at how to use each of them.
assertDataFrameEqual: This function allows you to compare two PySpark DataFrames for equality with a single line of code, checking whether the data and schemas match. It returns descriptive information when there are differences.
Let's walk through an example. First, we'll create two DataFrames, intentionally introducing a difference in the first row:
Then we'll call assertDataFrameEqual with the two DataFrames:
The function returns a descriptive message indicating that the first row in the two DataFrames is different. In this example, the first amounts listed for Alfred in this row are not the same (expected: 1500, actual: 1200):
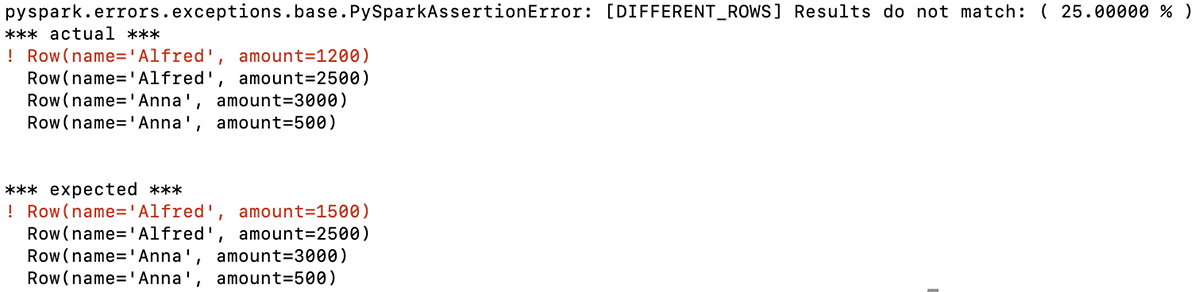
With this information, you immediately know the problem with the DataFrame your code generated and can target your debugging based on that.
The function also has several options to control the strictness of the DataFrame comparison so that you can adjust it according to your specific use cases.
assertSchemaEqual: This function compares only the schemas of two DataFrames; it does not compare row data. It lets you validate whether the column names, data types, and nullable property are the same for two different DataFrames.
Let's look at an example. First, we'll create two DataFrames with different schemas:
Now, let's call assertSchemaEqual with these two DataFrame schemas:
The function determines that the schemas of the two DataFrames are different, and the output indicates where they diverge:

In this example, there are two differences: the data type of the amount column is LONG in the actual DataFrame but DOUBLE in the expected DataFrame, and because we created the expected DataFrame without specifying a schema, the column names are also different.
Both of these differences are highlighted in the function output, as illustrated here.
assertPandasOnSparkEqual is not covered in this blog post since it is deprecated from Apache Spark 3.5.1 and scheduled to be removed in the upcoming Apache Spark 4.0.0. For testing Pandas API on Spark, see Pandas API on Spark equality test functions.
Structured output for debugging differences in PySpark DataFrames
While the assertDataFrameEqual and assertSchemaEqual functions are primarily aimed at unit testing, where you typically use smaller datasets to test your PySpark functions, you might use them with DataFrames with more than just a few rows and columns. In such scenarios, you can easily retrieve the row data for rows that are different to make further debugging easier.
Let's take a look at how to do that. We'll use the same data we used earlier to create two DataFrames:
And now we'll grab the data that differs between the two DataFrames from the assertion error objects after calling assertDataFrameEqual:
Creating a DataFrame based on the rows that are different and showing it, as we've done in this example, illustrates how easy it is to access this information:

As you can see, information on the rows that are different is immediately available for further analysis. You no longer have to write code to extract this information from the actual and expected DataFrames for debugging purposes.
This feature will be available from the upcoming Apache Spark 4.0 and DBR 14.3.
Pandas API on Spark equality test functions
In addition to the functions for testing the equality of PySpark DataFrames, Pandas API on Spark users will have access to the following DataFrame equality test functions:
assert_frame_equalassert_series_equalassert_index_equal
The functions provide options for controlling the strictness of comparisons and are great for unit testing your Pandas API on Spark DataFrames. They provide the exact same API as the pandas test utility functions, so you can use them without changing existing pandas test code that you want to run using Pandas API on Spark.
Here are a couple of examples demonstrating the use of assert_frame_equal with different parameters, comparing Pandas API on Spark DataFrames:
In this example, the schemas of the two DataFrames are different. The function output lists the differences, as shown here:

We can specify that we want the function to compare column data even when the columns do not have the same data type using the check_dtype argument, as in this example:
Since we specified that assert_frame_equal should ignore column data types, it now considers the two DataFrames equal.
These functions also allow comparisons between Pandas API on Spark objects and pandas objects, facilitating compatibility checks between different DataFrame libraries, as illustrated in this example:
Using the new PySpark DataFrame and Pandas API on Spark equality test functions is a great way to make sure your PySpark code works as expected. These functions help you not only catch errors but also understand exactly what has gone wrong, enabling you to quickly and easily identify where the problem is. Check out the Testing PySpark page for more information.
These functions will be available from the upcoming Apache Spark 4.0. DBR 14.2 already supports it.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.