2023 State of Data + AI

We’re in the golden age of data and AI. The unparalleled pace of AI discoveries, model improvements and new products on the market puts data and AI strategy at the top of conversations across every organization around the world. The next generation of winning companies and executives will be those who understand and leverage AI.
In our inaugural report, 2023 State of Data + AI, we examine trends in data and AI adoption across more than 9,000 global Databricks customers. The goal of this report is to help data leaders and executives understand the AI landscape and benchmark their own data investments and strategies.
2023 State of Data + AI covers the broader data estate to answer questions such as:
- How are organizations applying data science and machine learning (ML) in the real world?
- Which data and AI products are quickly rising to the top?
- How are organizations executing their data warehousing, especially within this new age of AI?
Here’s a snapshot of what we discovered:
NLP and LLMs
Key finding: Natural language processing and large language models are in high demand
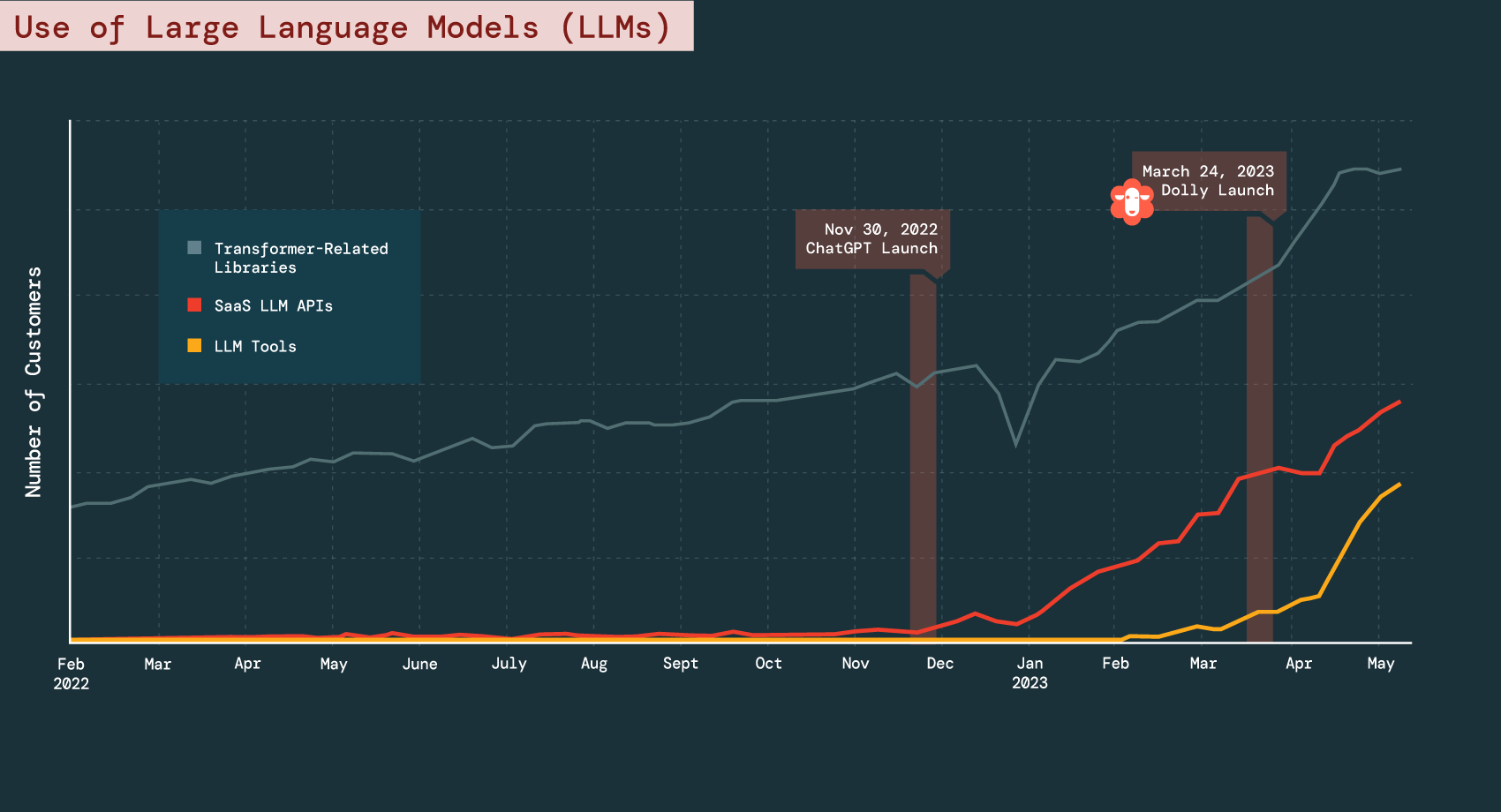
Our data shows that companies are understanding the value of ML and increasingly investing in cutting-edge tools, a trend underscored by the recent innovations in large language models (LLMs). We see SaaS LLMs — used to access models like OpenAI — growing exponentially in parallel with the launch of ChatGPT. In fact, the number of companies using SaaS LLM APIs has grown 1310% between the end of November 2022 and the beginning of May 2023.
Ultimately, we observed two accelerating trends: organizations are building their own LLMs, which models like Dolly show can be quite accessible and inexpensive, and they are using proprietary models like ChatGPT.
The Modern Data and AI Stack
Key finding: Data integration tools dominate
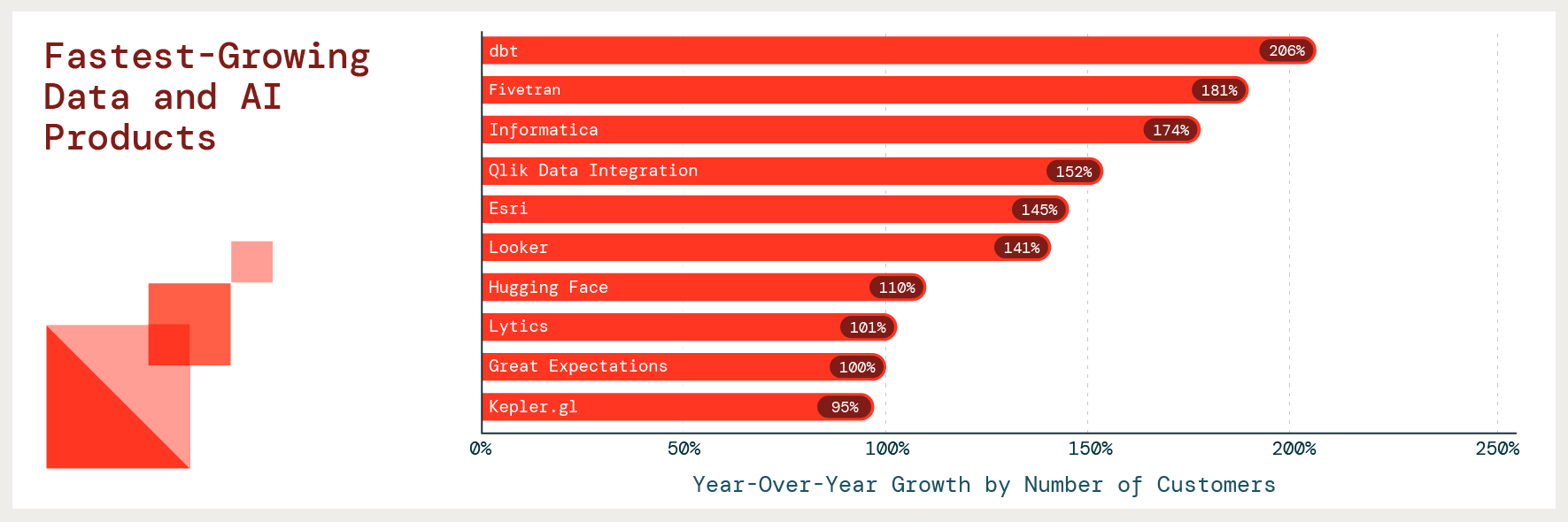
A common question we get from customers is, “What data and AI products are other companies using?”
We analyzed adoption and growth across hundreds of partners within our ecosystem. Our fastest-growing products tell a story of companies adding data integration tools so they can move quickly to develop more advanced use cases with their data. dbt reports the highest growth with a 206% YoY increase in the number of customers.
The Unification of Data and AI
Key finding: Organizations are unifying their data, analytics and AI on Lakehouse
With the explosion of data comes the growing volume of unstructured and semi-structured data, which traditionally required multiple platforms to manage alongside structured data. Lakehouse solves this problem by providing a unified platform for all data types and formats.
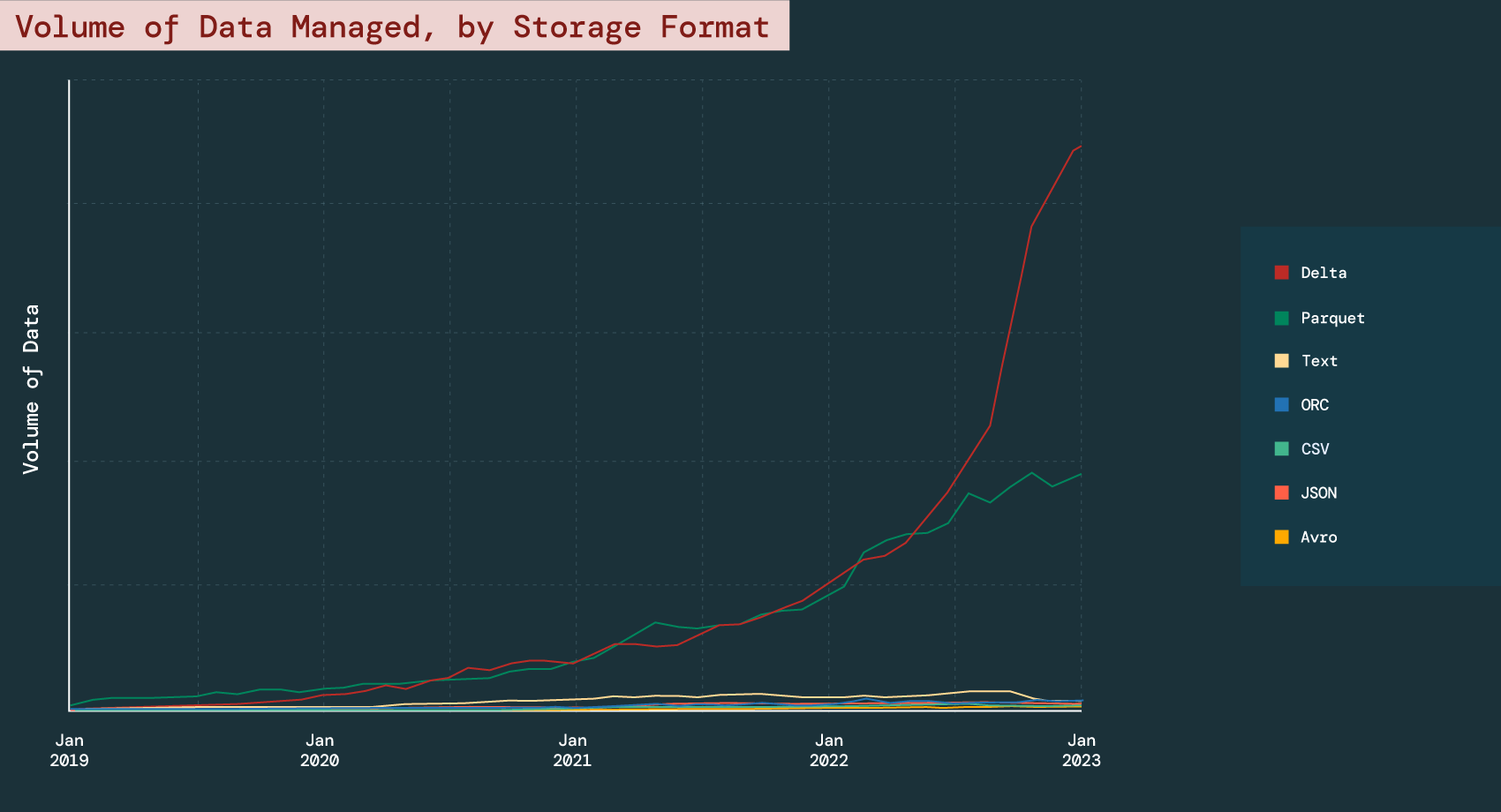
Delta Lake is the foundation of Lakehouse. When compared to the steady, flat or declining growth in other storage formats (e.g., text, JSON and CSV), our data shows that a growing number of organizations are turning to Delta Lake to manage their data with 304% YoY growth.