Announcing the General Availability of the Databricks SQL Statement Execution API
by Adriana Ispas, Chris Stevens, Christian Stuart and Sander Goos
Today, we are excited to announce the general availability of the Databricks SQL Statement Execution API on AWS and Azure, with support for GCP expected to be in Public Preview early next year. You can use the API to connect to your Databricks SQL warehouse over a REST API to access and manipulate data managed by the Databricks Lakehouse Platform.
In this blog, we walk through the API basics, discuss the key features newly available in the GA release, and show you how to build a data application using the Statement Execution API with the Databricks Python SDK. You can even follow along by running the code against your Databricks workspace. For an additional example, our previous blog showed how to leverage your data in a spreadsheet using the Statement Execution API and JavaScript.
Statement Execution API, in brief
BI applications are one of the major consumers of a data warehouse and Databricks SQL provides a rich connectivity ecosystem of drivers, connectors, and native integrations with established BI tools. Nevertheless, data managed by the Databricks Lakehouse Platform is relevant for applications and use cases beyond BI, such as e-commerce platforms, CRM systems, SaaS applications, or custom data applications developed by customers in-house. Often, these tools cannot easily connect over standard database interfaces and drivers; however, almost any tool and system can communicate with a REST API.
The Databricks SQL Statement Execution API allows you to use standard SQL over HTTP to build integrations with a wide range of applications, technologies, and computing devices. The API provides a set of endpoints that allow you to submit SQL statements to a SQL Warehouse for execution and retrieve results. The image below provides a high-level overview of a typical data flow.
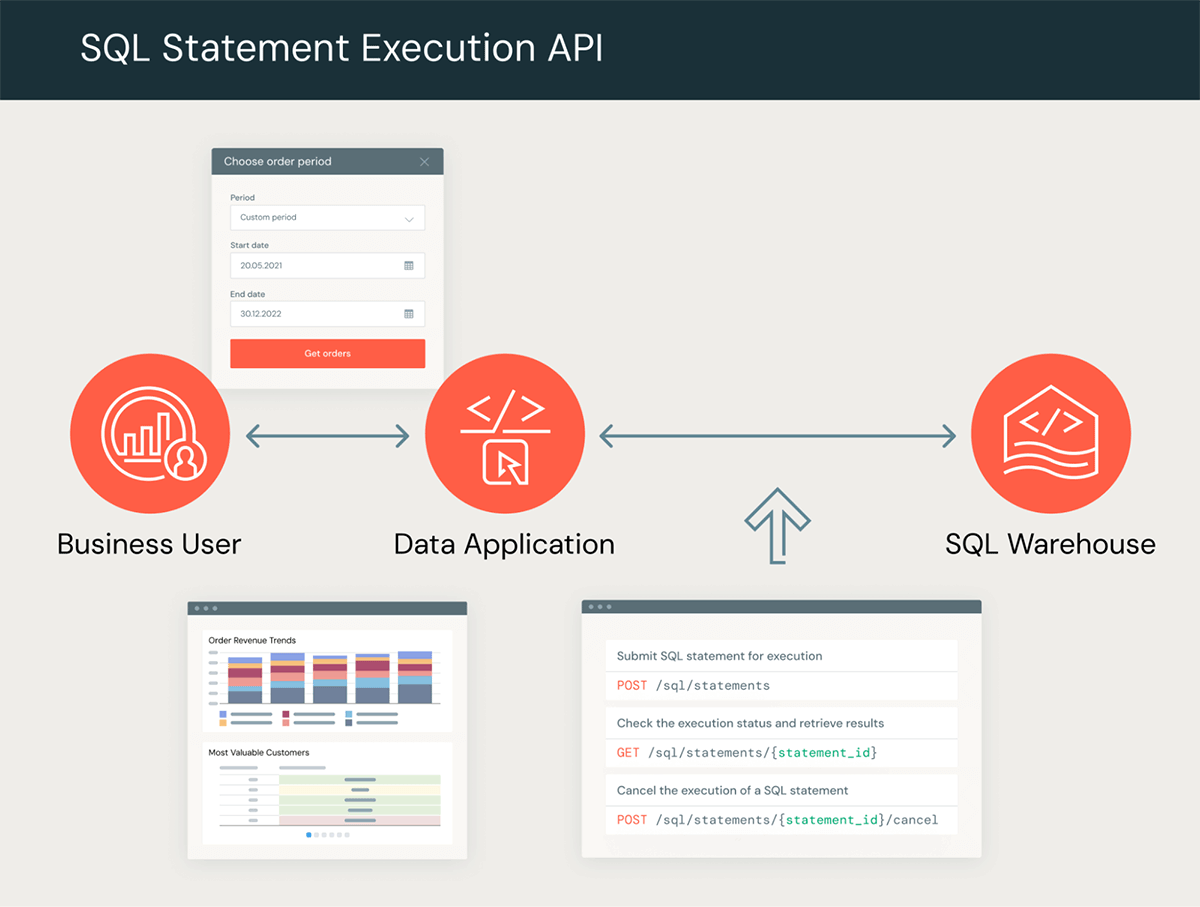
You can use the API to build custom data apps with tools and languages of your choice. For example, you can build web applications where a business user provides a set of querying criteria through a user interface and is provided back the results for visualization, download, or further analysis. You can also use the API to implement special-purpose APIs adapted to your particular use cases and microservices, or build custom connectors in your programming language of choice. One significant advantage when using the API for these scenarios is that you do not need to install a driver or manage database connections; you simply connect to the server over HTTP and manage asynchronous data exchanges.
New features available in the GA release
Along with the general availability of the API on AWS and Azure, we are enabling some new features and improvements.
- Parameterized statements - Safely apply dynamic literal values to your SQL queries with type-safe parameters. Literal values are handled separately from your SQL code, which allows Databricks SQL to interpret the logic of the code independently from user-supplied variables, preventing common SQL injection attacks.
- Result retention - Refetch the results for a statement multiple times for up to one hour. Previously, results were no longer available after the last chunk was read, requiring special treatment of the last chunk when fetching chunks in parallel.
- Multiple result formats - JSON_ARRAY and CSV formats are now available with the EXTERNAL_LINKS disposition. While you can still use Arrow for optimal performance, JSON and CSV are more ubiquitously supported by tools and frameworks, improving interoperability.
- Byte and row limits - Apply limits to your results to prevent unexpected large outputs. The API will return a truncation flag whenever the specified limit is exceeded.
In the next section, we will go into more detail as we use these new features to build a custom API on top of the Statement Execution API.
Build your special-purpose API
At the Data+AI Summit this year, we walked through building a custom API on top of the Databricks Lakehouse Platform using this new Statement Execution API. In case you missed it, we'll relive that journey now, developing a simple website and service backend for a fictional company called Acme, Inc. You can follow along with the code here, running the `setup.sh` script as a first step.
Acme, Inc. is a medium sized business with 100 stores that sell various types of machine parts. They leverage the Databricks Lakehouse to track information about each store and to process their sales data with a medallion architecture. They want to create a web application that allows store managers to easily browse their gold sales data and store information. In addition, they want to enable store managers to insert sales that didn't go through a normal point of sale. To build this system we'll create a Python Flask application that exposes a custom data API and an HTML/JQuery frontend that invokes that API to read and write data.
Let's look at the custom API endpoint to list all stores and how it maps to the Statement Execution API in the backend. It is a simple GET request that takes no arguments. The backend calls into the SQL Warehouse with a static SELECT statement to read the `stores` table.
| Acme Inc's API Request | Statement Execution API Request | |
|---|---|---|
| GET /stores | → | POST /sql/statements statement: "SELECT * FROM stores" wait_timeout: "50s" on_wait_timeout: "CANCEL" |
| Acme Inc's API Response | Statement Execution API Response | |
| state: "SUCCEEDED" stores: [ ["123", "Acme, Inc", …], ["456", "Databricks", …] ] |
← | statement_id: "ID123" status: { state: "SUCCEEDED" } manifest: { ... } result: { data_array: [ ["123", "Acme, Inc", …], ["456", "Databricks", …] ] } |
As Acme only has 100 stores, we expect a fast query and a small data set in the response. Therefore, we've decided to make a synchronous request to Databricks and get rows of store data returned inline. To make it synchronous, we set the `wait_timeout` to indicate we'll wait up to 50 seconds for a response and set the `on_wait_timeout` parameter to cancel the query if it takes longer. By looking at the response from Databricks, you'll see that the default result `disposition` and `format` return the data inline in a JSON array. Acme's backend service can then repackage that payload to return to the custom API's caller.
The full backend code for this custom endpoint can be found here. In the frontend, we call the custom `/api/1.0/stores` endpoint to get the list of stores and display them by iterating over the JSON array here. With these two pieces, Acme has a new homepage backed by Databricks SQL!
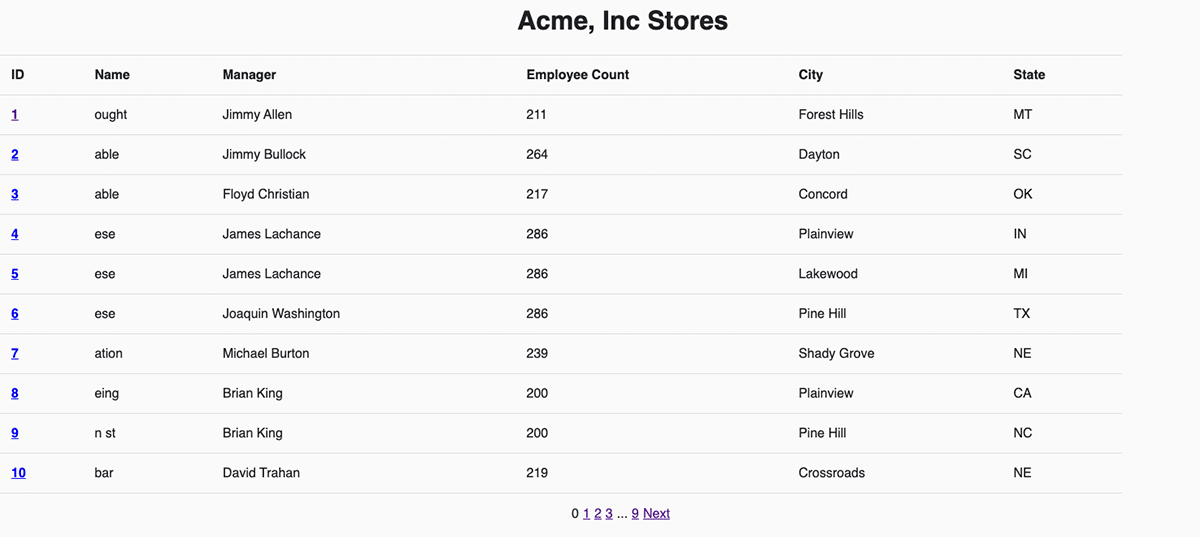
For each store, we also want to have a page that displays the most recent sales and we want a store manager to be able to download the full set of store data. It's worth noting that the number of sales transactions per store can be quite large - many orders of magnitude greater than the number of stores. The requirements for this custom API endpoint are:
- Limited output - The caller must be able to limit the number of sales returned so they don't have to get all the data all the time.
- Multi-format - The results should be retrievable in multiple formats so that they can be easily displayed in a web page or downloaded for offline processing in a tool like Excel.
- Async - It needs to be async as it might take a long time to get the sales information for a store.
- Efficient extracts - For performance and stability reasons, the large sales data should not be pulled through the backend web server.
Below, you can see how we use the Databricks SDK for Python to invoke the Statement Execution API to cover these requirements. The full code is here.
To meet the first two requirements, we expose `row_limit` and `format` parameters from the custom API and pass them to the Statement Execution API. This will allow callers to limit the total number of rows produced by the query and to pick the result format (CSV, JSON or Arrow).
To make the custom API asynchronous, we'll set the Statement Execution API's `wait_timeout` parameter to 0 seconds, which means Databricks will respond immediately with a statement ID and query state. We'll package that statement ID as a `request_id` along with the state in a response to the caller. Once the client gets the request ID and state, they can poll the same custom API endpoint to check the status of the execution. The endpoint forwards the request to Databricks SQL Warehouse via the `get_statement` method. If the query is successful, the API will eventually return a `SUCCEEDED` state along with a `chunk_count`. The chunk count indicates how many partitions the result was divided into.
To achieve efficient extracts (4th requirement), we used the EXTERNAL_LINKS disposition. This allows us to get a pre-signed URL for each chunk, which the custom API will return when given a `request_id` and `chunk_index`.
We can use this to build Acme a landing page for each store that shows the most recent sales by supplying a row limit of 20 and the JavaScript friendly JSON_ARRAY result format. But we can also add a "Download" button at the top of the page to allow store managers to pull historical data for all sales. In that case, we don't supply a limit and leverage the CSV format for easy ingestion into the analysis tool of their choice. Once the browser sees the query is successful and gets the total chunk count, it invokes the custom API in parallel to get pre-signed URLs and download the CSV data directly from cloud storage. Under the hood, the EXTERNAL_LINKS disposition leverages the Cloud Fetch technology that has shown a 12x improvement in extraction throughput over sequential inline reads. In the example below, we downloaded 500MBs in parallel at ~160Mbps.
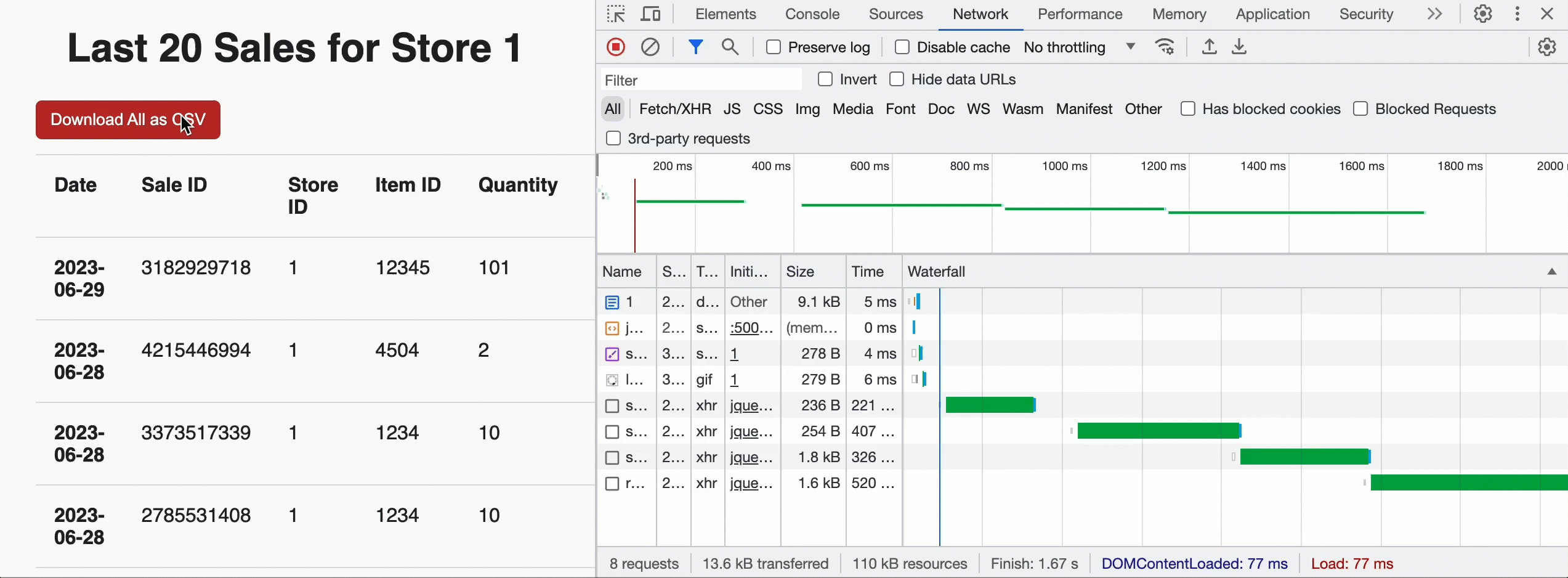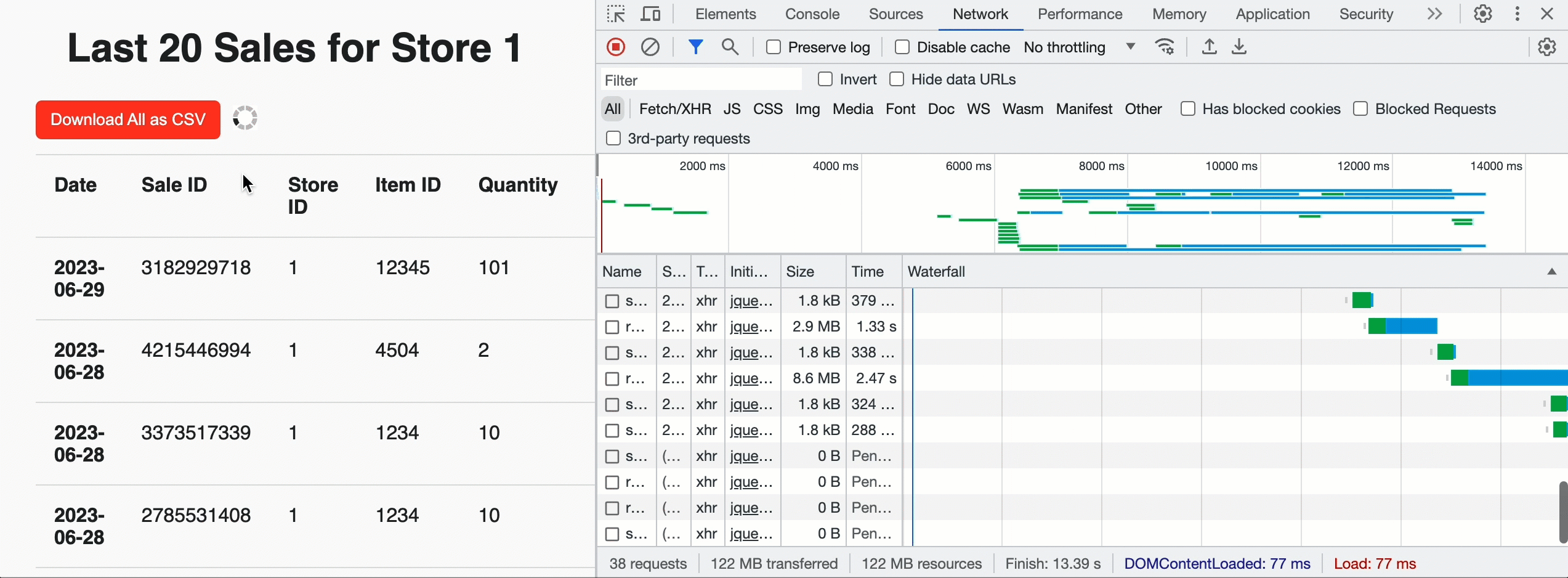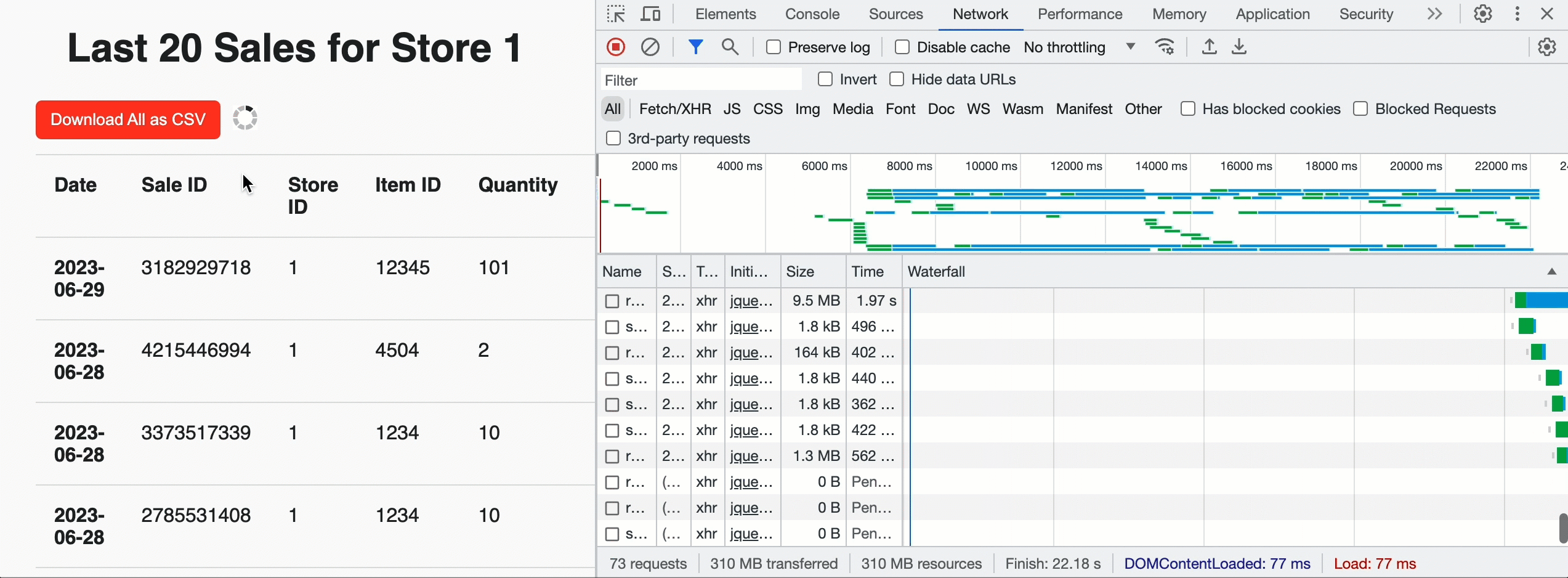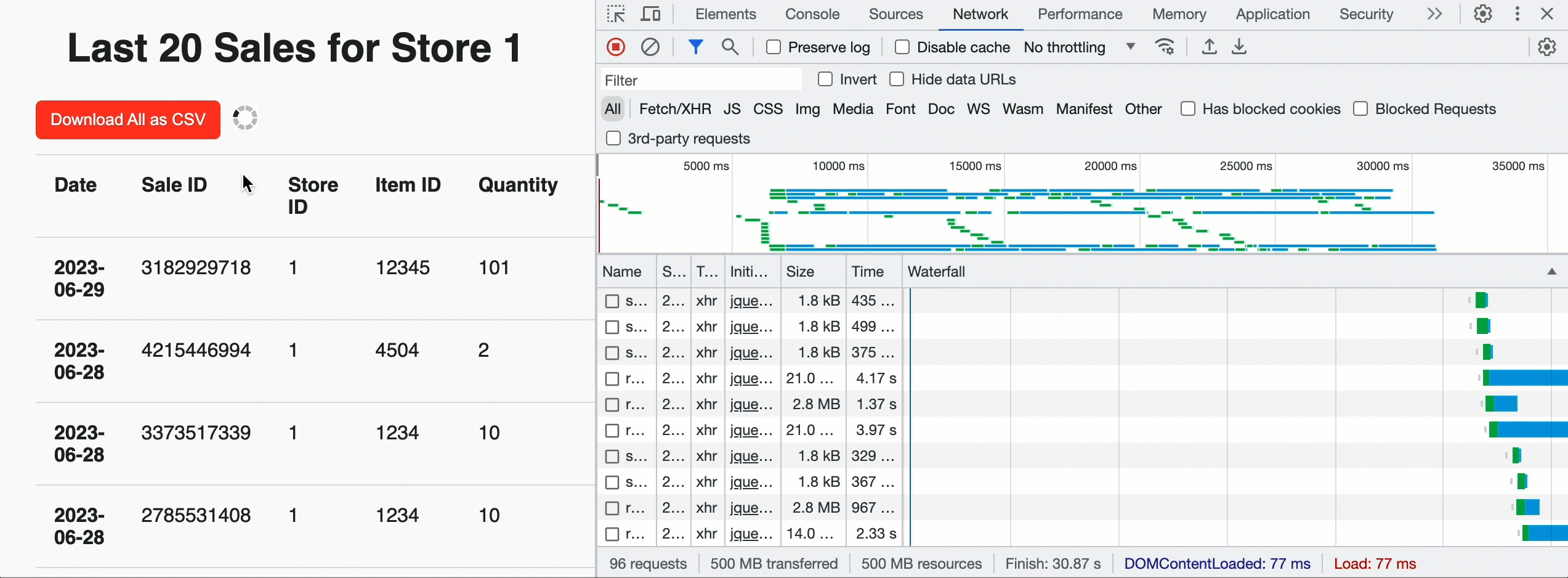
Now that sales for a store can be viewed, the Acme team also needs to be able to insert new sales information into the Lakehouse. For that, we can create a simple web form backed by a POST request to the /api/1.0/stores/storeId/sales endpoint. To get the form data into the Lakehouse, we'll use a parameterised SQL statement:
And supply the input from the web form to the Statement Execution API using the `parameters` list argument with a name, value, and type for each parameter:
The SQL Warehouse engine will safely substitute the provided parameters into the query plan as literals after parsing the SQL code. This prevents maliciously injected SQL syntax from being interpreted as SQL. The "type" field for each parameter provides an additional layer of safety by checking the type-correctness of the provided "value". If a malicious user provides a value like "100); drop table sales" as input for the quantity field, the INSERT INTO statement will result in the following error and will not be executed:
[INVALID_PARAMETER_MARKER_VALUE.INVALID_VALUE_FOR_DATA_TYPE] An invalid parameter mapping was provided: the value '100); drop table sales' for parameter 'quantity' cannot be cast to INT because it is malformed.
You can see how we put parameters to use as part of the `POST /api/1.0/stores/store_id/sales` endpoint here. If the input to the web form is valid with the correct types, then the sales table will be successfully updated after the user clicks "Submit".
You can now iterate on top of this custom API or use it as a stepping stone to building your own custom data application on top of the Databricks Lakehouse Platform. In addition to using the sample code we've been using throughout this article and the `setup.sh` script that creates sample tables in your own Databricks environment, you may want to watch the live explanation at the Data+AI Summit – the video below.
Getting started with the Databricks SQL Statement Execution API
The Databricks SQL Statement Execution API is available with the Databricks Premium and Enterprise tiers. If you already have a Databricks account, follow our tutorial (AWS | Azure), the documentation (AWS | Azure), or check our repository of code samples. If you are not an existing Databricks customer, sign up for a free trial.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.