

Lakehouse AI: A Data-Centric Approach to Building Generative AI Applications
Generative AI will have a transformative impact on every business. Databricks has been pioneering AI innovations for a decade, actively collaborating with thousands...
Have you ever deployed an AI model, only to discover it's delivering unexpected results in a real-world setting? Monitoring models is as crucial as their deployment. That's why we're excited to introduce Inference Tables to simplify monitoring and diagnostics for AI models. Inference Tables enable you to continuously capture input and predictions from Databricks Model Serving endpoints and log them into a Unity Catalog Delta Table. You can then leverage existing data tools, including Lakehouse Monitoring, to monitor, debug, and optimize your AI models.
Inference Tables are a great example of the value you get when doing AI on a Lakehouse platform. Without any additional complexity and cost, you can enable monitoring on every deployed model. This allows you to detect issues early and take immediate action, such as by retraining, to consistently achieve the best business outcomes from your AI models.
"Databricks Lakehouse AI provides us with a unified environment to train, deploy, and monitor various machine learning models. Using Inference Tables, we are able to monitor and debug deployed models which help us to maintain the model performance over time. This is enabling us to deliver improved models for a better customer experience on Housing.com"— Dr. Anil Goyal, Principal Data Scientist at Housing.com
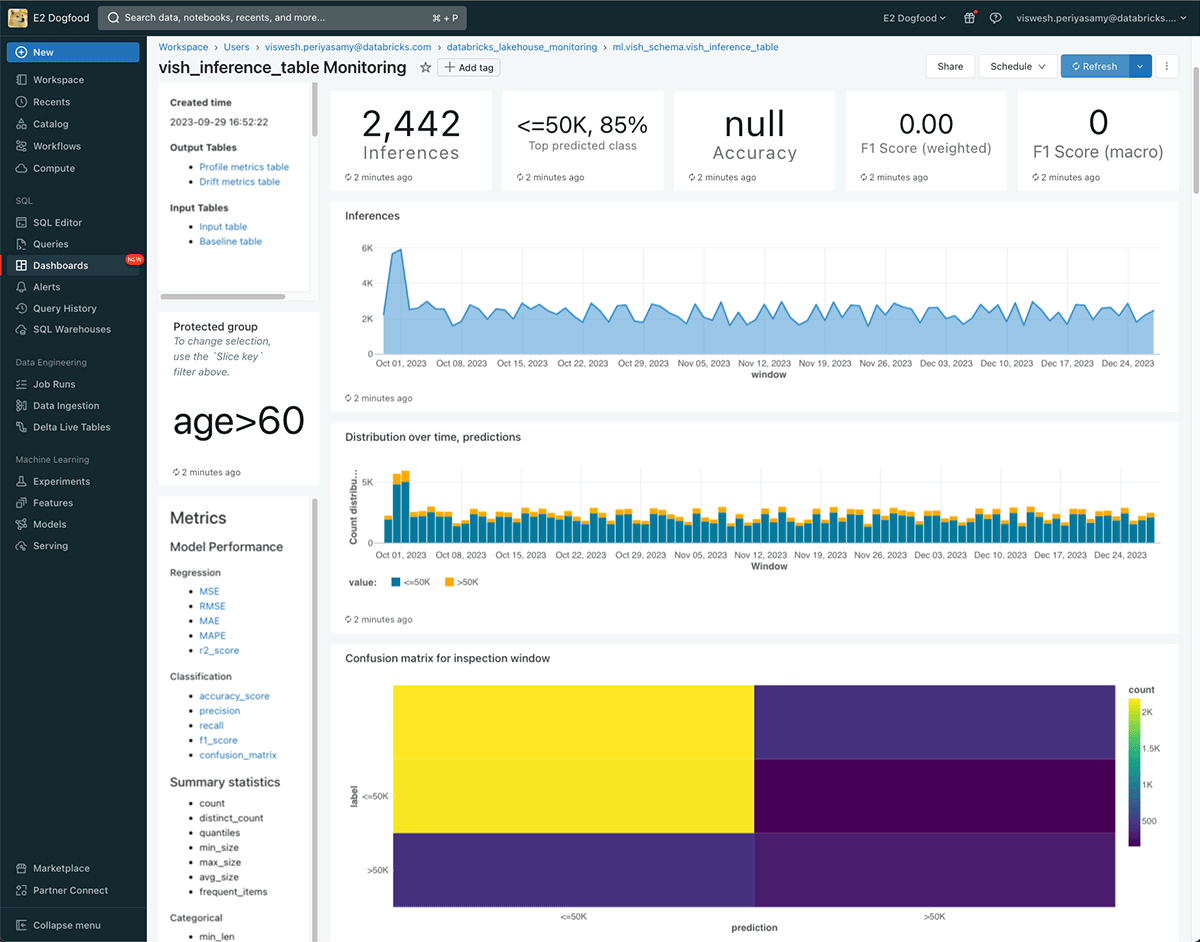
Inference Tables are a Unity Catalog-managed Delta Table that stores online prediction requests and responses from model serving endpoints. Once enabled, Inference Tables become a powerful tool for various use cases, including monitoring, debugging, creation of training corpora, and compliance audits. Instead of creating separate tools for each purpose, Inference Tables provide a table representation of a model so that consistent governance and monitoring tools can be used across all stages of ML.
You can simply enable Inference Tables on both existing and new model-serving endpoints with a single click. Prediction requests and responses will begin logging into the Unity Catalog Governed table, making it easy to discover, govern, and share these Tables with teams.

You can continuously monitor your model performance and data drift using Lakehouse Monitoring—the first monitoring solution designed for both AI and data assets. Lakehouse Monitoring automatically generates data and ML quality dashboards which can be easily shared with stakeholders. Additionally, you can enable alerts to know when you need to retrain your model based on fundamental shifts in data or reductions in model performance. Thanks to this simplification, quality no longer has to remain an afterthought and can be enabled on all endpoints.
"With Databricks Model Serving, we can now train, deploy, monitor, and retrain machine learning models, all on the same platform. By bringing model serving (and monitoring) together with the feature store, we can ensure deployed models are always up-to-date and delivering accurate results. This streamlined approach allows us to focus on maximizing the business impact of AI without worrying about availability and operational concerns."— Don Scott, VP Product Development at Hitachi Solutions
Inference Tables simplify the debugging process by logging all the important data you need: HTTP status codes, model execution times, and other endpoint-specific details. The best part? There's no need to learn new tools. You can debug endpoints by analyzing the Inference Table with queries in Databricks SQL or use Python in a notebook for advanced post-analysis.
You can also replay past traffic to new models with the historical data in Inference Tables. With this capability, you can easily generate a side-by-side comparison of model latencies. You can further tie this data into our LLM evaluation suite to evaluate different LLMs for safety and quality.

With your data in the Unity Catalog, you can easily join Inference Tables with ground truth labels to create a robust training corpus for improving your models. If you don't have labels, you can generate them through our partnership with Labelbox and easily combine them with Inference Tables. You can then fine-tune these models or even automate retraining using Databricks Workflows. This continuous feedback loop ensures you always obtain the best predictions from your model.

"We chose Databricks Model Serving as Inference Tables are pivotal for our continuous retraining capability - allowing seamless integration of input and predictions with minimal latency. Additionally, it offers a straightforward configuration to send data to delta tables, enabling the use of familiar SQL and workflow tools for monitoring, debugging, and automating retraining pipelines. This guarantees that our customers consistently benefit from the most updated models."— Shu Ming Peh, Lead Machine Learning Engineer at Hipages Group

