


Hello Dolly: Democratizing the magic of ChatGPT with open models
Update Apr 12, 2023: We have released Dolly 2.0, licensed for both research and commercial use. See the new blog post here...
This post and accompanying notebook and tutorial video demonstrate how to use Cleanlab Studio to improve the performance of Large Language Models (LLMs, also known as foundation models) by improving data they are fine-tuned on, an approach called Data-centric AI (DCAI). As a case study, we explore one of the most popular use cases of LLMs — fine-tuning the model for text classification — on the Stanford politeness classification dataset.
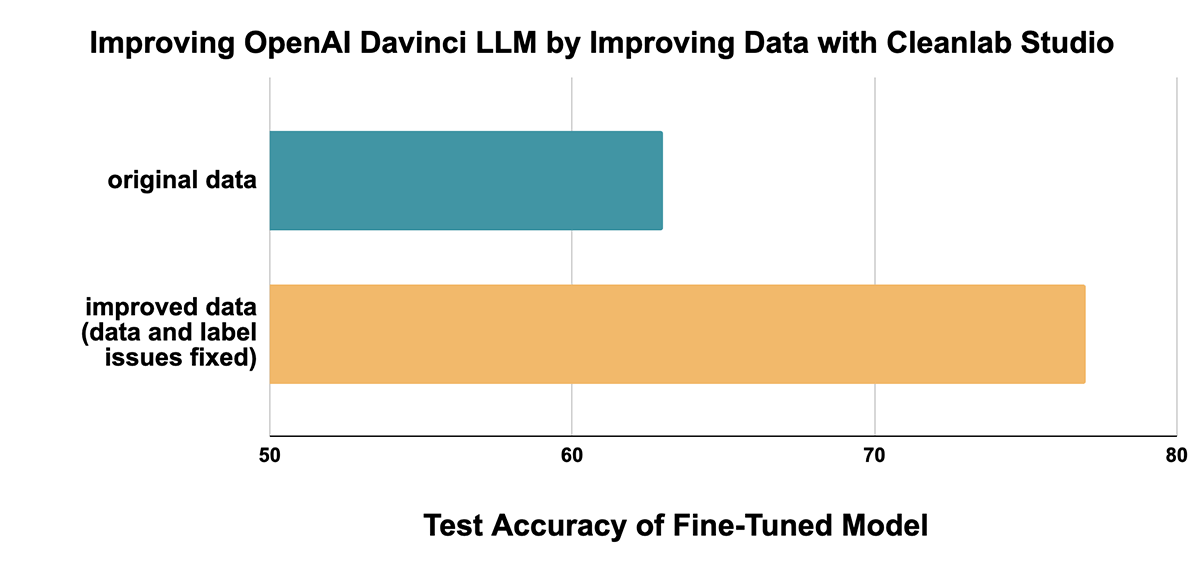
In this post, we'll see how Cleanlab Studio systematically improves the training data to boost LLM performance by 37% without spending any time or resources to change the model architecture, hyperparameters, or the training process.
Data powers AI/ML in the enterprise, but real-world datasets have been found to contain between 7-50% annotation errors. Bad data as a whole is a trillion-dollar problem. Unsurprisingly, erroneous data, from imperfectly-labeled data to outliers, hampers the training (and evaluation) of ML models across tasks like intent recognition, entity recognition, and sequence generation, and the effect can be severe. LLMs are no exception: although pre-trained LLMs are equipped with a lot of world knowledge, their performance is adversely affected by noisy training data, as noted by OpenAI.
This post demonstrates the impact of bad data for fine-tuning LLMs and examines how using Cleanlab Studio to improve the training data can mitigate the negative effects of bad data (such as erroneous labels) without requiring machine learning expertise, writing any code, or spending any time or resources to change the model architecture, hyperparameters, or training process.
Because Cleanlab Studio works with data (regardless of which model is used) it remains applicable for LLMs that are yet to be invented, like GPT-10.
LLMs have recently become ubiquitous for their powerful generative and discriminative capabilities, but they can struggle to produce reliable outputs for a particular business use-case. Often, training on domain-specific labeled data (called fine-tuning an LLM) is required.
In this post, we fine-tune LLM's using the APIs offered by OpenAI. You can also fine-tune open-source LLMs like Dolly or MPT-7B directly on Databricks. Most data annotation processes inevitably introduce label errors in domain-specific training data that can negatively impact fine-tuning and evaluation accuracy of LLMs, whether you are using APIs or open-source LLMs.
Here is a quote from OpenAI on their strategy for training state-of-the-art AI systems:
"We prioritized filtering out all of the bad data over leaving in all of the good data… we can always fine-tune our model with more data later, but it's much harder to make the model forget something that it has already learned."
Some organizations like OpenAI manually handle issues in their data to produce robust and reliable ML models, but this can be prohibitively expensive for many organizations! Cleanlab Studio uses advanced algorithms out of MIT called confident learning to systematically improve your dataset with less effort by automatically finding and fixing issues in most types of real-world data (image, text, tabular, audio, etc.). Cleanlab Studio includes a Databricks connector to easily improve the quality of data you have stored on Databricks.
Beyond boosting LLM performance, Cleanlab Studio is an end-to-end platform for (1) turning unreliable data into reliable insights for business intelligence and analytics teams and (2) training reliable AI solutions on potentially unreliable data for MLOps and technology teams. The platform is free to try at: https://cleanlab.ai/.
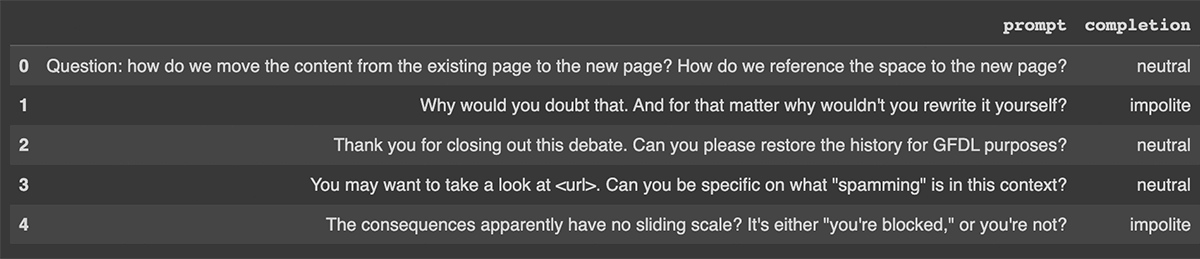
In our case study, we consider a variant of the Stanford Politeness Dataset which has text phrases labeled as one of three classes: impolite, neutral, or polite. Labeled by human annotators, some of the labels are naturally low-quality.
This post and accompanying notebook and tutorial video walk through how to:
The training dataset (download) has 1916 examples each labeled by a single human annotator; naturally, such a labeling process is unreliable, as humans make mistakes. The test dataset (download) has 480 examples each labeled by five annotators; we use the consensus label as a high-quality approximation of the true politeness (measuring test accuracy against these consensus labels). To ensure a fair comparison, this test dataset remains fixed throughout our experiments (all label cleaning / dataset modification is only done in the training set).
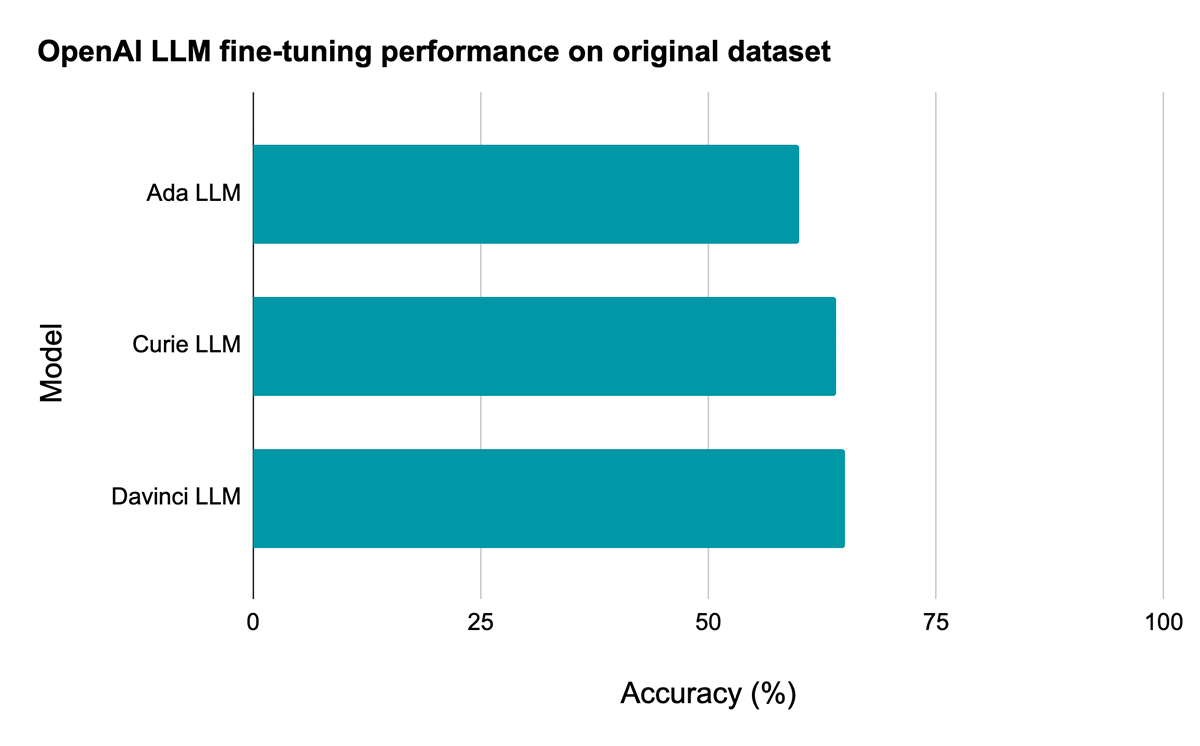
The accompanying notebook walks through how to download the dataset into DBFS, use Spark to preprocess the data, prepare files that are ready to upload to the OpenAI API, and invoke the OpenAI API to fine-tune a model. The Davinci model, the most powerful of the three models evaluated here, achieves a test set accuracy of 65% when fine-tuned on the original (low-quality) training dataset.
Using the Databricks connector for Cleanlab Studio to upload our dataset using just 1 line of code, we can have sophisticated data-centric AI algorithms find errors in our data.
> cleanlab_studio.upload_dataset(politeness_train)Cleanlab Studio helps you not only automatically find issues in your data, but also fix your data using a human-in-the-loop approach, where the tool shows you the data that's flagged to be erroneous and presents suggestions on how to handle it (e.g., changing a label or marking a data point as an outlier and removing it from the dataset).
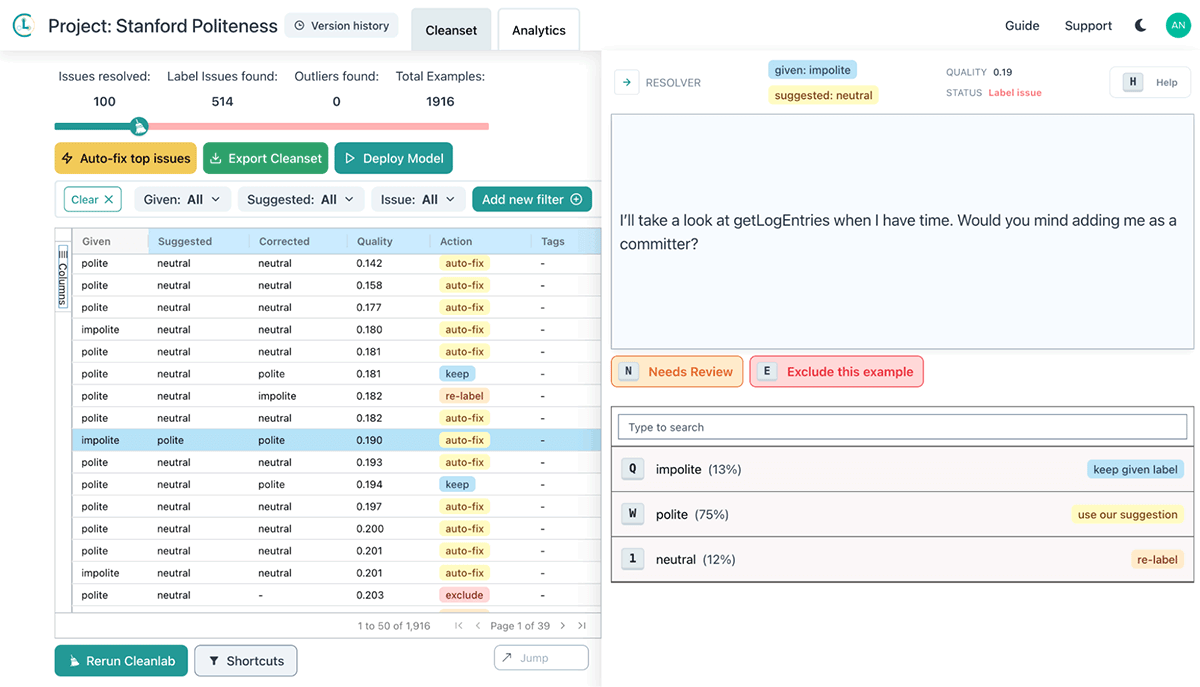
In our case study, we used this human-in-the-loop approach to efficiently find and fix erroneous data points in the training set. After that, with just 1 more line of code, we can import the improved dataset back into Databricks:
> politeness_train_fixed = cleanlab_studio.apply_corrections(id, politeness_train)We repeat the same evaluation, fine-tuning the LLM on the improved dataset obtained from Cleanlab Studio and computing test accuracy (on the same test set), and we see a dramatic improvement across model types:
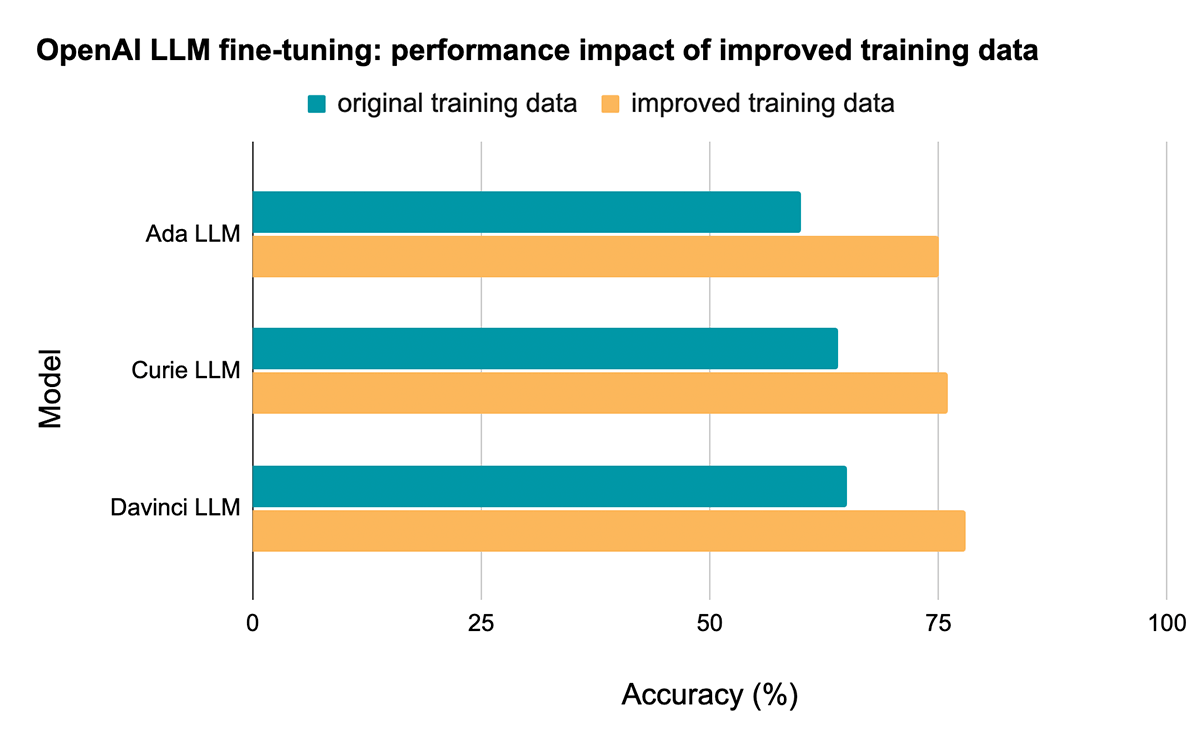
On the Davinci model, for example, performance improves from 65% test accuracy to 78% test accuracy, a reduction in error rate of 37%, simply by improving the quality of the training data!
Errors like outliers and label issues are common in real-world datasets, and these errors can have a dramatic impact on the reliability and robustness of ML models trained on this data as well as insights and analytics obtained. Cleanlab Studio is a solution for dealing with erroneous or noisy data via AI automated techniques to help avoid the tedious manual effort that data scientists often dread. Cleanlab Studio helps you efficiently find and fix data and label issues for any ML model (not just LLMs) and most types of data (not just text, but also images, audio, tabular data, etc.) without requiring you to write code or have any ML expertise. In the case study in this post, we saw how Cleanlab Studio boosted the performance of an LLM fine-tuned for a classification task by 37% without spending any time or resources to change the model architecture, hyperparameters, or the training process.
Because Cleanlab Studio improves models and insights by improving the underlying data, it works for any model or LLM that exists today or may exist in the future and will only become better at identifying issues as more accurate models are released!

