Wie man den Datenfluss zwischen Databricks und SAS beschleunigt
von Oleg Mikhov und Satish Garla
Dies ist ein gemeinsamer Beitrag von Databricks und T1A. Wir danken Oleg Mikhov, Solutions Architect bei T1A, für seine Beiträge.
Dies ist der erste Beitrag in einer Reihe von Blogs über die Best Practices für die Zusammenführung der Databricks Lakehouse Platform und SAS. Ein früherer Databricks Blogbeitrag stellte Databricks und PySpark für SAS-Entwickler vor. In diesem Beitrag diskutieren wir Möglichkeiten zum Datenaustausch zwischen SAS und der Databricks Lakehouse Platform sowie Möglichkeiten zur Beschleunigung des Datenflusses. In zukünftigen Beiträgen werden wir die Erstellung effizienter Daten- und Analyse-Pipelines untersuchen, die beide Technologien umfassen.
Datengesteuerte Organisationen übernehmen die Lakehouse Plattform schnell, um mit den ständig wachsenden Geschäftsanforderungen Schritt zu halten. Die Lakehouse-Plattform ist zur neuen Norm für Organisationen geworden, die Datenplattformen und -architekturen aufbauen möchten. Die Modernisierung beinhaltet die Verlagerung von Daten, Anwendungen oder anderen Geschäftselementen in die Cloud. Die Umstellung auf die Cloud ist jedoch ein schrittweiser Prozess, und es ist geschäftskritisch, weiterhin von Legacy-Investitionen so lange wie möglich zu profitieren. Vor diesem Hintergrund neigen viele Unternehmen dazu, mehrere Daten- und Analyseplattformen zu haben, bei denen die Plattformen koexistieren und sich ergänzen.
Eine der Kombinationen, die wir sehen, ist die Verwendung von SAS mit dem Databricks Lakehouse. Es gibt viele Vorteile, wenn die beiden Plattformen effizient zusammenarbeiten können, wie zum Beispiel:
- Größere und skalierbare Datenspeicherfähigkeiten von Cloud-Plattformen
- Größere Rechenkapazität durch den Einsatz von Technologien wie Apache Spark™, die nativ mit paralleler Verarbeitungsfähigkeit entwickelt wurden
- Größere Compliance mit Data Governance und Management durch Delta Lake
- Senkung der Kosten für Datenanalyse-Infrastrukturen durch vereinfachte Architekturen
Einige häufig beobachtete Anwendungsfälle und Gründe für Data Science und Datenanalyse sind:
- SAS-Praktiker nutzen SAS für seine Kernstatistiken-Pakete, um erweiterte Analyseergebnisse zu entwickeln, die regulatorische Anforderungen erfüllen, während sie Databricks Lakehouse für Datenmanagement, ELT-Verarbeitung und Data Governance nutzen
- In SAS entwickelte Machine-Learning-Modelle werden auf riesigen Datenmengen mit der parallelen Verarbeitungsarchitektur der Apache Spark-Engine auf der Lakehouse-Plattform bewertet
- SAS-Datenanalysten erhalten schnelleren Zugriff auf große Datenmengen auf der Lakehouse-Plattform für Ad-hoc-Analysen und Berichte mithilfe von Databricks SQL-Endpunkten und High-Bandwidth-Konnektoren
- Erleichtern Sie die Cloud-Modernisierung und die Migrationsreise durch die Einrichtung eines hybriden Workstreams, der sowohl Cloud-Architektur als auch lokale SAS-Plattform umfasst
Eine zentrale Herausforderung dieser Koexistenz ist jedoch, wie die Daten performant zwischen den beiden Plattformen ausgetauscht werden. In diesem Blog teilen wir Best Practices, die T1A für seine Kunden implementiert hat, und Benchmark-Ergebnisse, die verschiedene Methoden zum Verschieben von Daten zwischen Databricks und SAS vergleichen.
Szenarien
Der beliebteste Anwendungsfall ist ein SAS-Entwickler, der auf Daten im Lakehouse zugreifen möchte. Die Analyse-Pipelines, die beide Technologien umfassen, erfordern einen bidirektionalen Datenfluss: Daten von Databricks nach SAS und Daten von SAS nach Databricks.
- Zugriff auf Delta Lake von SAS: Ein SAS-Benutzer möchte auf Big Data in Delta Lake mit der SAS-Programmiersprache zugreifen.
- Zugriff auf SAS-Datensätze von Databricks: Ein Databricks-Benutzer möchte auf SAS-Datensätze, im Allgemeinen die sas7bdat-Datensätze, als DataFrame zugreifen, um sie in Databricks-Pipelines zu verarbeiten oder im Delta Lake für unternehmensweiten Zugriff zu speichern.
In unseren Benchmark-Tests haben wir das folgende Umgebungssetup verwendet:
- Microsoft Azure als Cloud-Plattform
- SAS 9.4M7 auf Azure (Single-Node-Standard-VM D8s v3)
- Databricks Runtime 9.0, Apache Spark 3.1.2 (2 Knoten Standard DS4v2 Cluster)
Abbildung 1 zeigt das konzeptionelle Architekturdiagramm mit den diskutierten Komponenten. Databricks Lakehouse sitzt auf Azure Data Lake Storage mit Delta Lake Medallion-Architektur. SAS 9.4, installiert auf einer Azure VM, verbindet sich mit Databricks Lakehouse, um Daten mithilfe der in den folgenden Abschnitten diskutierten Verbindungsoptionen zu lesen/schreiben.
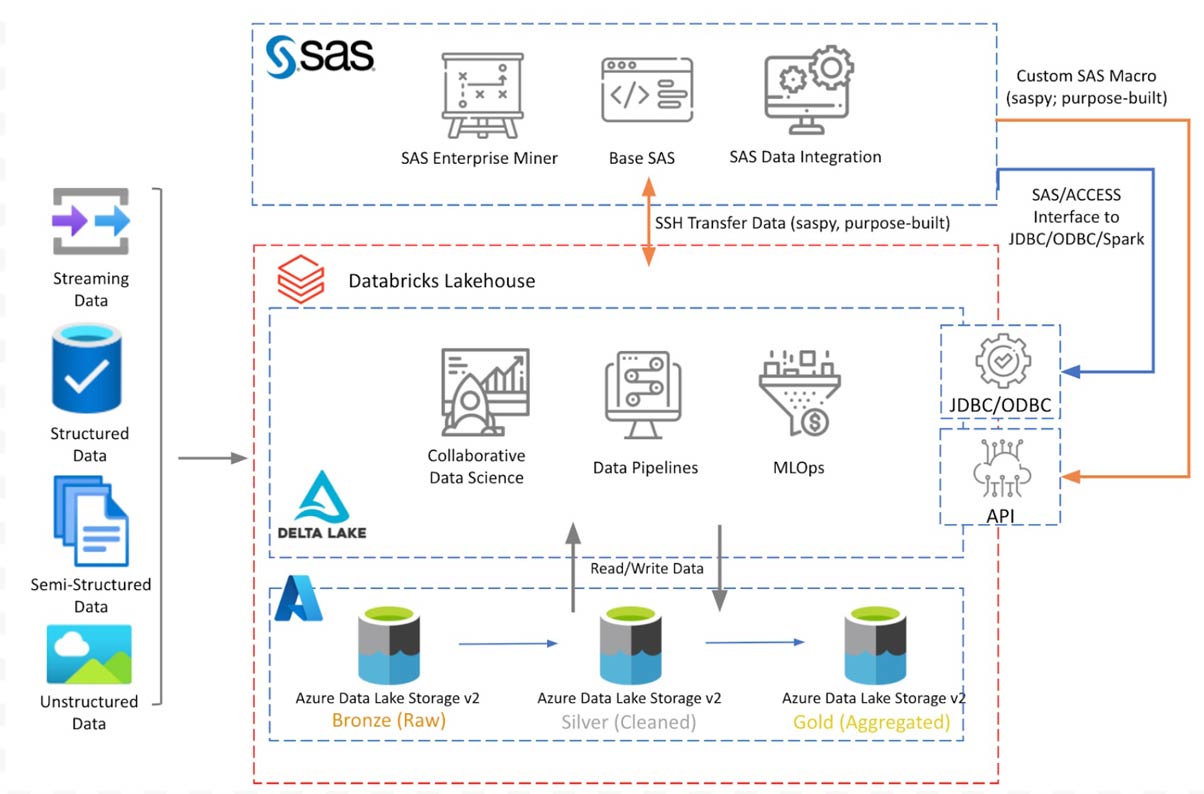
Das obige Diagramm zeigt eine konzeptionelle Architektur von Databricks, das auf Azure bereitgestellt wird. Die Architektur wird auf anderen Cloud-Plattformen ähnlich sein. In diesem Blog diskutieren wir nur die Integration mit der SAS 9.4-Plattform. In einem späteren Blogbeitrag werden wir diese Diskussion erweitern, um auf Lakehouse-Daten von SAS Viya zuzugreifen.
Zugriff auf Delta Lake von SAS
Stellen Sie sich vor, wir haben eine Delta Lake-Tabelle, die in einem SAS-Programm verarbeitet werden muss. Wir wünschen uns die beste Leistung beim Zugriff auf diese Tabelle und vermeiden gleichzeitig mögliche Probleme mit der Datenintegrität oder der Kompatibilität von Datentypen. Es gibt verschiedene Möglichkeiten, Datenintegrität und Kompatibilität zu erreichen. Nachfolgend diskutieren wir einige Methoden und vergleichen sie hinsichtlich Benutzerfreundlichkeit und Leistung.
In unseren Tests haben wir den eCommerce-Verhaltensdatensatz (5,67 GB, 9 Spalten, ca. 42 Millionen Datensätze) von Kaggle verwendet.
Datenquellen-Hinweis: eCommerce-Verhaltensdaten aus einem Multi-Kategorie-Store und REES46 Marketing Platform.
Getestete Methoden
1. Verwendung von SAS/ACCESS Interface-Konnektoren
Traditionell nutzen SAS-Benutzer SAS/ACCESS-Software, um sich mit externen Datenquellen zu verbinden. Sie können entweder eine SAS LIBNAME-Anweisung verwenden, die auf den Databricks-Cluster verweist, oder die SQL-Pass-Through-Funktion nutzen. Derzeit gibt es für SAS 9.4 drei verfügbare Verbindungsoptionen.
SAS/ACCESS Interface zu Spark wurde kürzlich mit Funktionen und exklusivem Support für Databricks-Cluster ausgestattet. Sehen Sie sich dieses Video für eine kurze Demonstration an. Das Video erwähnt SAS Viya, aber dasselbe gilt für SAS 9.4.
Codebeispiele zur Verwendung dieser Konnektoren finden Sie in diesem Git-Repository: T1A Git - SAS Libraries Examples.
2. Verwendung des saspy-Pakets
Die Open-Source-Bibliothek saspy von SAS Institute ermöglicht es Databricks Notebook-Benutzern, SAS-Anweisungen von einer Python-Zelle im Notebook auszuführen, um Code auf dem SAS-Server auszuführen, sowie Daten aus SAS-Datensätzen in Pandas DataFrames zu importieren und zu exportieren.
Da sich dieser Abschnitt auf den Zugriff auf Lakehouse-Daten durch einen SAS-Programmierer mit SAS-Programmierung konzentriert, wurde diese Methode in ein SAS-Makroprogramm integriert, ähnlich der im nächsten Abschnitt diskutierten zweckgebundenen Integrationsmethode.
Um eine bessere Leistung mit diesem Paket zu erzielen, haben wir die Konfiguration mit einer definierten char_length-Option getestet (Details finden Sie hier). Mit dieser Option können wir Längen für Zeichenfelder im Datensatz definieren. In unseren Tests brachte die Verwendung dieser Option eine zusätzliche Leistungssteigerung von 15 %. Für die Transportschicht zwischen den Umgebungen haben wir die saspy-Konfiguration mit einer SSH-Verbindung zum SAS-Server verwendet.
3. Verwendung einer zweckgebundenen Integration
Obwohl die beiden oben genannten Methoden ihre Vorteile haben, kann die Leistung weiter verbessert werden, indem einige der Mängel der vorherigen Methoden, die im nächsten Abschnitt (Testergebnisse) diskutiert werden, behoben werden. Vor diesem Hintergrund haben wir ein SAS-Makro-basiertes Integrationsdienstprogramm entwickelt, das sich primär auf Leistung und Benutzerfreundlichkeit für SAS-Benutzer konzentriert. Das SAS-Makro kann einfach in bestehenden SAS-Code integriert werden, ohne Kenntnisse der Databricks-Plattform, Apache Spark oder Python erforderlich zu sein.
Das Makro orchestriert einen mehrstufigen Prozess mithilfe der Databricks API:
- Weisen Sie den Databricks-Cluster an, Daten gemäß der bereitgestellten SQL-Abfrage abzurufen und zu extrahieren und die Ergebnisse im DBFS zu cachen, wobei die verteilten Verarbeitungsfunktionen von Spark SQL genutzt werden.
- Komprimieren und sicheres Übertragen des Datensatzes an den SAS-Server (CSV in GZIP) über SSH
- Entpacken und Importieren von Daten in SAS, um sie dem Benutzer in der SAS-Bibliothek zur Verfügung zu stellen. In diesem Schritt nutzen Sie die Spaltenmetadaten aus dem Databricks-Datenkatalog (Spaltentypen, -längen und -formate) für eine konsistente, korrekte und effiziente Datendarstellung in SAS.
Beachten Sie, dass die Integration für Datentypen mit variabler Länge verschiedene Konfigurationsoptionen unterstützt, je nachdem, was am besten zu den Benutzeranforderungen passt, wie z. B.:
- Notwendigkeit der Verwendung eines konfigurierbaren Standardwerts
- Profiling von bis zu 10.000 Zeilen (+ zusätzlicher Puffer), um den größten Wert zu ermitteln
- Profiling der gesamten Spalte im Datensatz, um den größten Wert zu ermitteln
Eine vereinfachte Version des Codes finden Sie hier: T1A Git - SAS DBR Custom Integration.
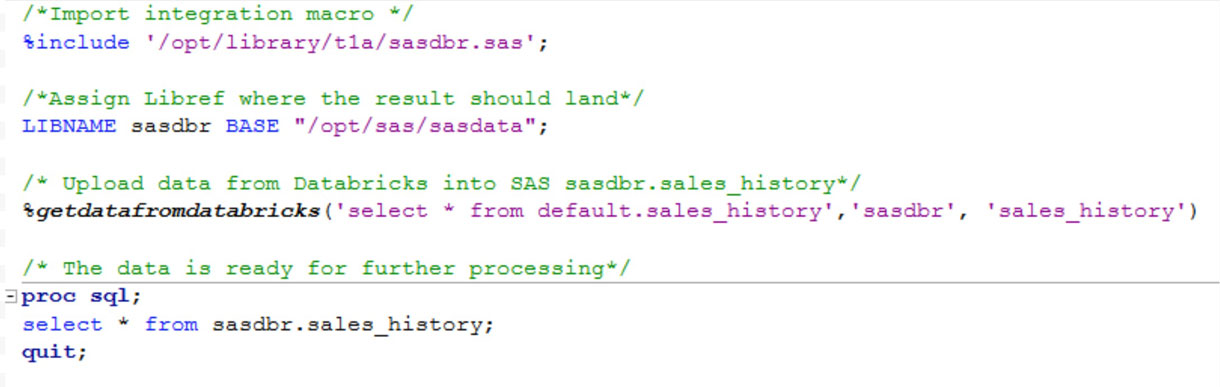
Die Endbenutzerverwendung dieses SAS-Makros sieht wie unten gezeigt aus und erfordert drei Eingaben:
- SQL-Abfrage, basierend auf der Daten aus Databricks extrahiert werden
- SAS-Libref, in der die Daten landen sollen
- Name, der dem SAS-Datensatz gegeben werden soll
Testergebnisse
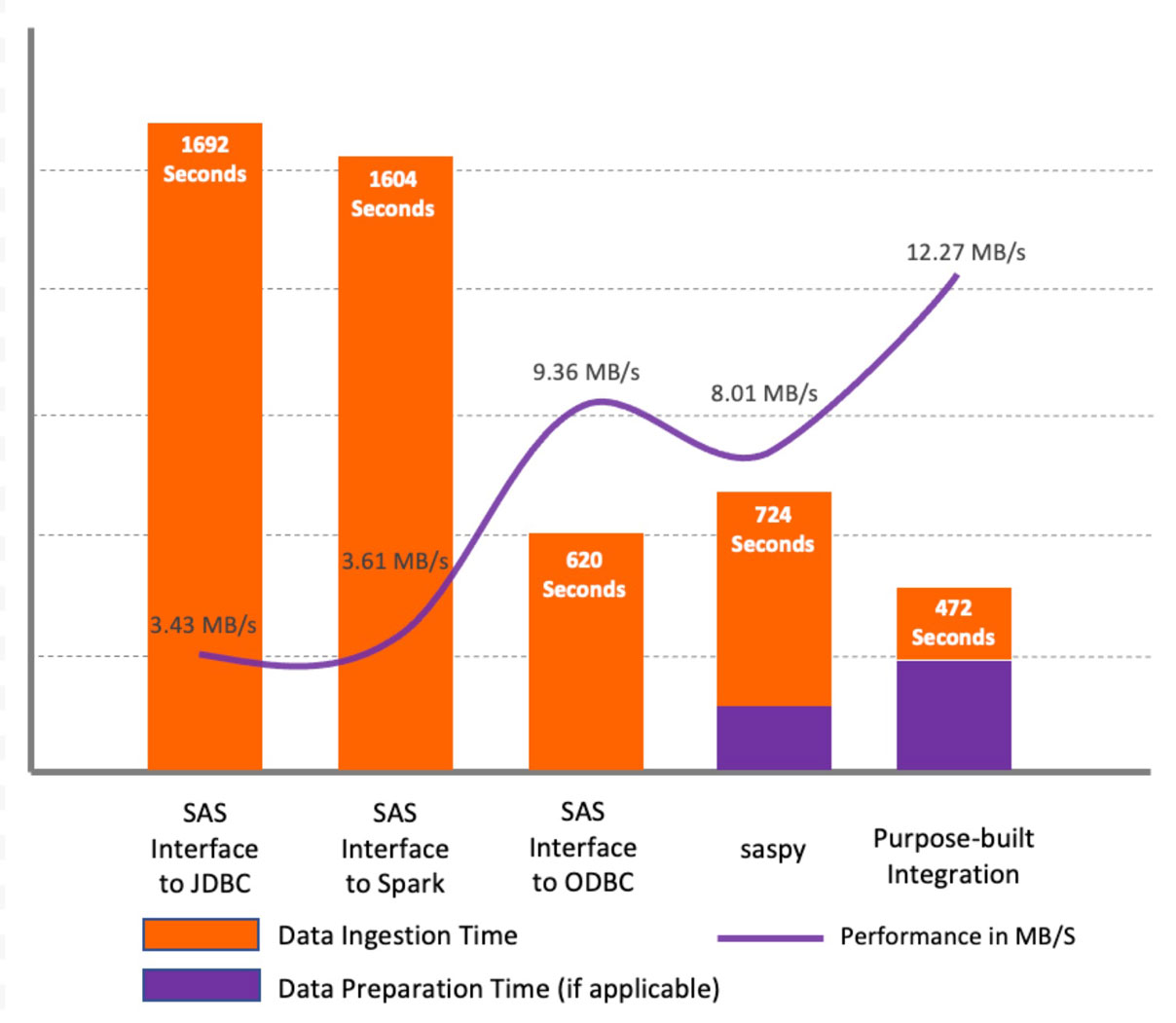
Wie im obigen Diagramm gezeigt, zeigen die Ergebnisse für den Testdatensatz, dass SAS/ACCESS Interface to JDBC und SAS/ACCESS Interface to Apache Spark eine ähnliche Leistung aufwiesen und im Vergleich zu anderen Methoden schlechter abschnitten. Der Hauptgrund dafür ist, dass die JDBC-Methoden keine Zeichenspalten in Datensätzen profilieren, um die richtige Spaltenlänge im SAS-Datensatz festzulegen. Stattdessen definieren sie die Standardlänge für alle Zeichensplattentypen (String und Varchar) als 765 Symbole. Dies führt nicht nur zu Leistungsproblemen bei der anfänglichen Datenabfrage, sondern auch bei der gesamten weiteren Verarbeitung. Außerdem verbraucht es erheblich zusätzlichen Speicherplatz. In unseren Tests endeten wir mit einem 216 GB großen Datensatz in der WORK-Bibliothek aus einem Quell-Datensatz von 5,6 GB. Mit SAS/ACCESS Interface to ODBC betrug die Standardlänge jedoch 255 Symbole, was zu einer erheblichen Leistungssteigerung führte.
Die Verwendung von SAS/ACCESS Interface-Methoden ist die bequemste Option für bestehende SAS-Benutzer. Bei der Verwendung dieser Methoden sind einige wichtige Überlegungen zu beachten:
- Beide Lösungen unterstützen implizite Abfrage-Pass-Through, jedoch mit einigen Einschränkungen:
- SAS/ACCESS Interface to JDBC/ODBC unterstützt nur Pass-Through für PROC SQL-Anweisungen.
- Zusätzlich zum PROC SQL-Pass-Through unterstützt SAS/ACCESS Interface to Apache Spark das Pass-Through für die meisten SQL-Funktionen. Diese Methode ermöglicht auch das Pushen gängiger SAS-Prozeduren an Databricks-Cluster.
- Das zuvor beschriebene Problem mit der Festlegung der Länge für die Zeichensplalten. Als Workaround schlagen wir die Verwendung der DBSASTYPE-Option vor, um die Spaltenlänge für SAS-Tabellen explizit festzulegen. Dies hilft bei der weiteren Verarbeitung des Datensatzes, beeinträchtigt jedoch nicht die anfängliche Datenabfrage aus Databricks.
- SAS/ACCESS Interface to Apache Spark/JDBC/ODBC erlaubt nicht das Kombinieren von Tabellen aus verschiedenen Databricks-Datenbanken (Schemas), die als verschiedene Librefs in derselben Abfrage zugewiesen sind (Verknüpfen), mit der Pass-Through-Funktion. Stattdessen wird die gesamte Tabelle nach SAS exportiert und in SAS verarbeitet. Als Workaround schlagen wir vor, ein dediziertes Schema in Databricks zu erstellen, das Ansichten basierend auf Tabellen aus verschiedenen Datenbanken (Schemas) enthält.
Die Verwendung der saspy-Methode zeigte eine etwas bessere Leistung im Vergleich zu SAS/ACCESS Interface to JDBC/Spark-Methoden. Der Hauptnachteil ist jedoch, dass die saspy-Bibliothek nur mit pandas DataFrames funktioniert, eine erhebliche Belastung für das Apache Spark-Treiberprogramm darstellt und der gesamte DataFrame in den Speicher geladen werden muss.
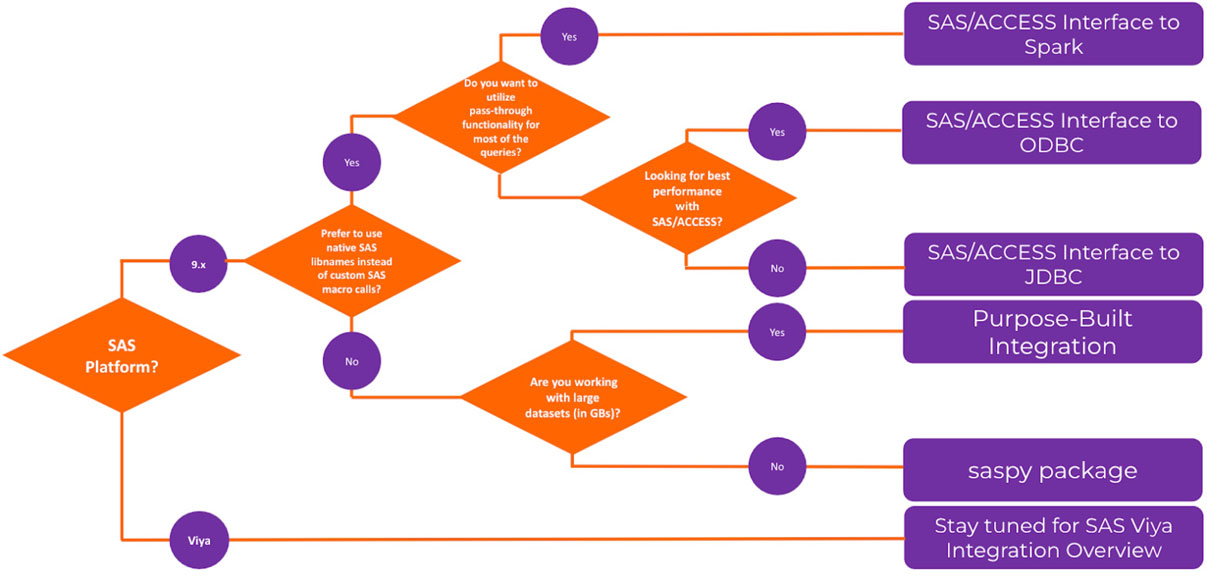
Die Methode der zweckgebundenen Integration zeigte die beste Leistung im Vergleich zu anderen getesteten Methoden. Abbildung 3 zeigt ein Flussdiagramm mit allgemeinen Anleitungen zur Auswahl der diskutierten Methoden.
SAS-Datensätze aus Databricks abrufen
Dieser Abschnitt befasst sich mit der Notwendigkeit für Databricks-Entwickler, SAS-Datensätze in Delta Lake aufzunehmen und sie in Databricks für Business Intelligence, visuelle Analysen und andere fortgeschrittene Analysen verfügbar zu machen. Während einige der zuvor beschriebenen Methoden hier anwendbar sind, werden einige zusätzliche Methoden diskutiert.
Im Test beginnen wir mit einem SAS-Datensatz (im sas7bdat-Format) auf dem SAS-Server, und am Ende haben wir diesen Datensatz als Spark DataFrame (wenn die Lazy-Invocation anwendbar ist, erzwingen wir das Laden von Daten in einen DataFrame und messen die Gesamtzeit) in Databricks verfügbar.
Wir haben für dieses Szenario die gleiche Umgebung und denselben Datensatz verwendet wie im vorherigen Szenario. Die Tests berücksichtigen nicht den Anwendungsfall, bei dem ein SAS-Benutzer einen Datensatz mit SAS-Programmierung in Delta Lake schreibt. Dies erfordert die Berücksichtigung von Tools und Funktionen von Cloud-Anbietern, die in einem späteren Blogbeitrag besprochen werden.
Getestete Methoden
1. Verwendung des saspy-Pakets von SAS
Die sd2df-Methode in der saspy-Bibliothek konvertiert einen SAS-Datensatz in einen pandas DataFrame, wobei SSH für die Datenübertragung verwendet wird. Sie bietet mehrere Optionen für den Staging-Speicher (Memory, CSV, DISK) während der Übertragung. In unserem Test zeigte die CSV-Option, die PROC EXPORT CSV-Datei und pandas read_csv()-Methoden verwendet, was die empfohlene Option für große Datensätze ist, die beste Leistung.
2. Verwendung der pandas-Methode
Seit frühen Versionen ermöglicht pandas Benutzern das Lesen von sas7bdat-Dateien über die pandas.read_sas API. Die SAS-Datei muss für das Python-Programm zugänglich sein. Häufig verwendete Methoden sind FTP, HTTP oder die Verschiebung in Cloud-Objektspeicher wie S3. Wir haben stattdessen einen einfacheren Ansatz gewählt, um eine SAS-Datei vom entfernten SAS-Server auf den Databricks-Cluster zu verschieben, indem wir SCP verwenden.
3. Verwendung von spark-sas7bdat
Spark-sas7bdat ist ein Open-Source-Paket, das speziell für Apache Spark entwickelt wurde. Ähnlich wie bei der pandas.read_sas()-Methode muss die SAS-Datei auf dem Dateisystem verfügbar sein. Wir haben die sas7bdat-Datei von einem entfernten SAS-Server mit SCP heruntergeladen.
4. Verwendung einer zweckgebundenen Integration
Eine weitere untersuchte Methode ist die Verwendung herkömmlicher Techniken mit Schwerpunkt auf dem Ausgleich von Komfort und Leistung. Diese Methode abstrahiert Kernintegrationen und wird dem Benutzer als Python-Bibliothek zur Verfügung gestellt, die von Databricks Notebooks ausgeführt wird.
- Verwenden Sie das saspy-Paket, um einen SAS-Makrocode (auf einem SAS-Server) auszuführen, der Folgendes tut:
- Exportieren von sas7bdat in eine CSV-Datei mithilfe von SAS-Code
- Komprimieren der CSV-Datei zu GZIP
- Verschieben der komprimierten Datei mit SCP auf den Databricks-Cluster-Treiberknoten
- Dekompression der CSV-Datei
- Lesen der CSV-Datei in einen Apache Spark DataFrame
Testergebnisse
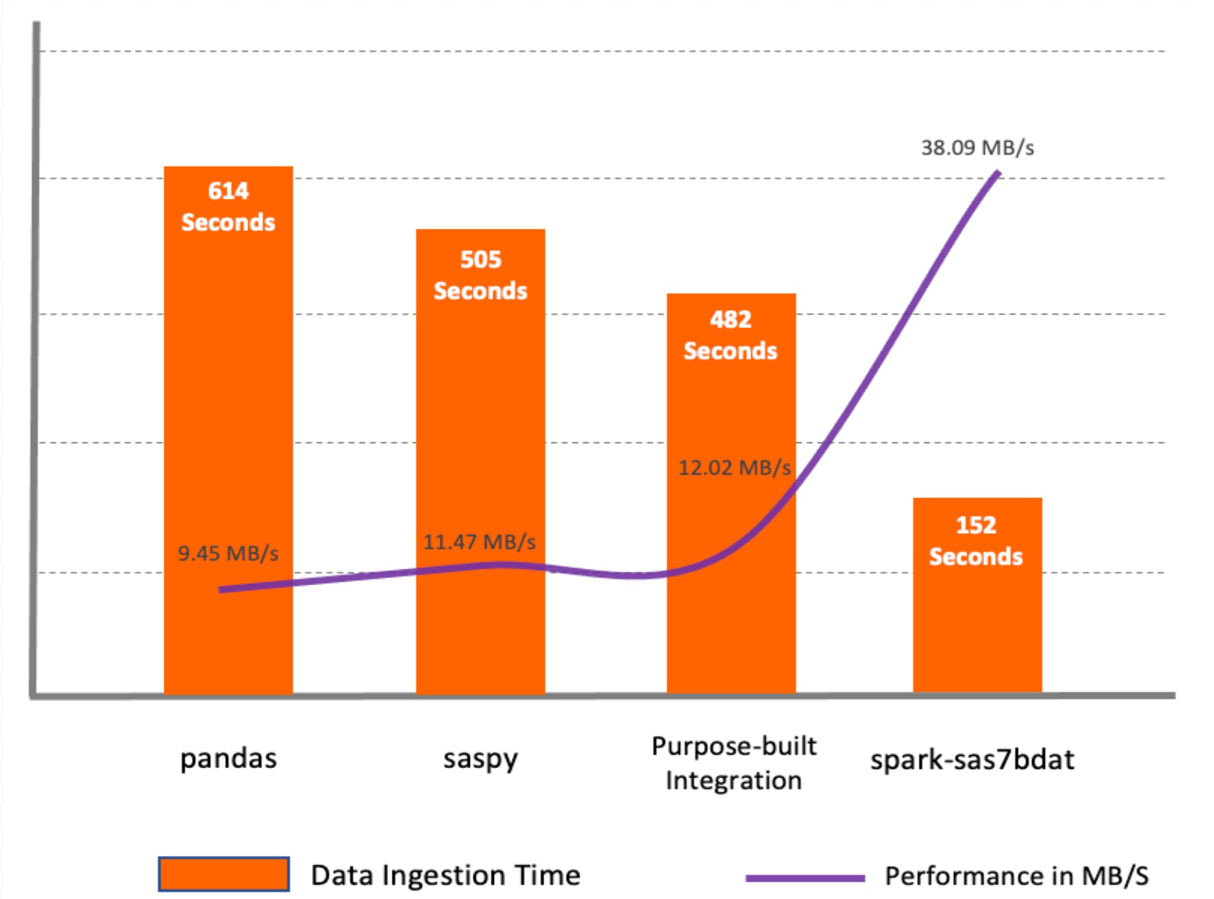
Das spark-sas7bdat-Paket zeigte die beste Leistung unter allen Methoden. Dieses Paket nutzt die parallele Verarbeitung von Apache Spark voll aus. Es verteilt Blöcke von sas7bdat-Dateien auf Worker-Knoten. Der Hauptnachteil dieser Methode ist, dass sas7bdat ein proprietäres Binärformat ist und die Bibliothek auf Reverse Engineering dieses Binärformats basiert. Daher unterstützt sie nicht alle Arten von sas7bdat-Dateien und wird auch nicht offiziell (kommerziell) vom Anbieter unterstützt.
Die Methoden saspy und pandas sind ähnlich, da sie beide für eine Single-Node-Umgebung entwickelt wurden und Daten in einen pandas DataFrame lesen, was einen zusätzlichen Schritt erfordert, bevor die Daten als Spark DataFrame verfügbar sind.
Das Makro purpose-built integration zeigte eine bessere Leistung im Vergleich zu saspy und pandas, da es Daten über Apache Spark APIs aus CSV liest. Es erreicht jedoch nicht die Leistung des spark-sas7bdat-Pakets. Die zweckgebundene Methode kann in einigen Fällen praktisch sein, da sie die Anwendung von Zwischen-Datentransformationen auf dem SAS-Server ermöglicht.
Fazit
Immer mehr Unternehmen setzen auf den Aufbau eines Databricks Lakehouse, und es gibt verschiedene Möglichkeiten, über andere Technologien auf Daten aus dem Lakehouse zuzugreifen. Dieser Blogbeitrag diskutiert, wie SAS-Entwickler, Data Scientists und andere Business-Anwender die Daten im Lakehouse nutzen und die Ergebnisse in die Cloud schreiben können. In unserem Experiment haben wir mehrere verschiedene Methoden zum Lesen und Schreiben von Daten zwischen Databricks und SAS getestet. Die Methoden unterscheiden sich nicht nur in der Leistung, sondern auch in der Benutzerfreundlichkeit und den zusätzlichen Funktionen, die sie bieten.
Für diesen Test haben wir die SAS 9.4M7-Plattform verwendet. SAS Viya unterstützt die meisten der diskutierten Ansätze, bietet aber auch zusätzliche Optionen. Wenn Sie mehr über die Methoden oder andere spezialisierte Integrationsansätze erfahren möchten, die hier nicht behandelt werden, können Sie sich gerne an uns wenden unter Databricks oder databricks@t1a.com.
In den kommenden Beiträgen dieser Blog-Serie werden wir Best Practices für die Implementierung integrierter Datenpipelines, End-to-End-Workflows unter Verwendung von SAS und Databricks sowie die Nutzung von SAS In-Database-Technologien für das Scoring von SAS-Modellen in Databricks-Clustern diskutieren.
SAS® und alle anderen Produkt- oder Dienstleistungsnamen von SAS Institute Inc. sind eingetragene Marken oder Marken von SAS Institute Inc. in den USA und anderen Ländern. ® kennzeichnet die Registrierung in den USA.
Erste Schritte
Probieren Sie den Kurs Databricks for SAS Users auf der Databricks Academy aus, um grundlegende praktische Erfahrungen mit PySpark-Programmierung für SAS-Programmiersprachenkonstrukte zu sammeln, und kontaktieren Sie uns, um mehr darüber zu erfahren, wie wir Ihr SAS-Team unterstützen können, ihre ETL-Workloads auf Databricks zu übertragen und Best Practices zu implementieren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.