Delta Lake UniForm
High-performance, format-agnostic storage for your open data lakehouse


Delta Lake UniForm unifies the data in your lakehouse, across all formats and types, for all your analytics and AI workloads.

Open across formats
Use your existing analytics and AI tools, regardless of open data format. UniForm automatically and instantly translates across formats, so you can keep a single copy of source data and still use your favorite Iceberg or Hudi client to read your Delta tables through the Unity Catalog endpoint. With UniForm, your data stays portable, with no vendor lock-in.
Connected across ecosystems
Delta Lake has a vast connector ecosystem and supports multiple frameworks and languages. Delta Sharing is the industry’s first open protocol for secure data sharing, making it simple to share data with other organizations regardless of where the data lives. Native integration with Unity Catalog allows you to centrally manage and audit shared data across organizations. This lets you confidently share data assets with suppliers and partners for better coordination of your business while meeting security and compliance needs. And through integrations with leading tools and platforms, you can visualize, query, enrich and govern shared data from your tools of choice.
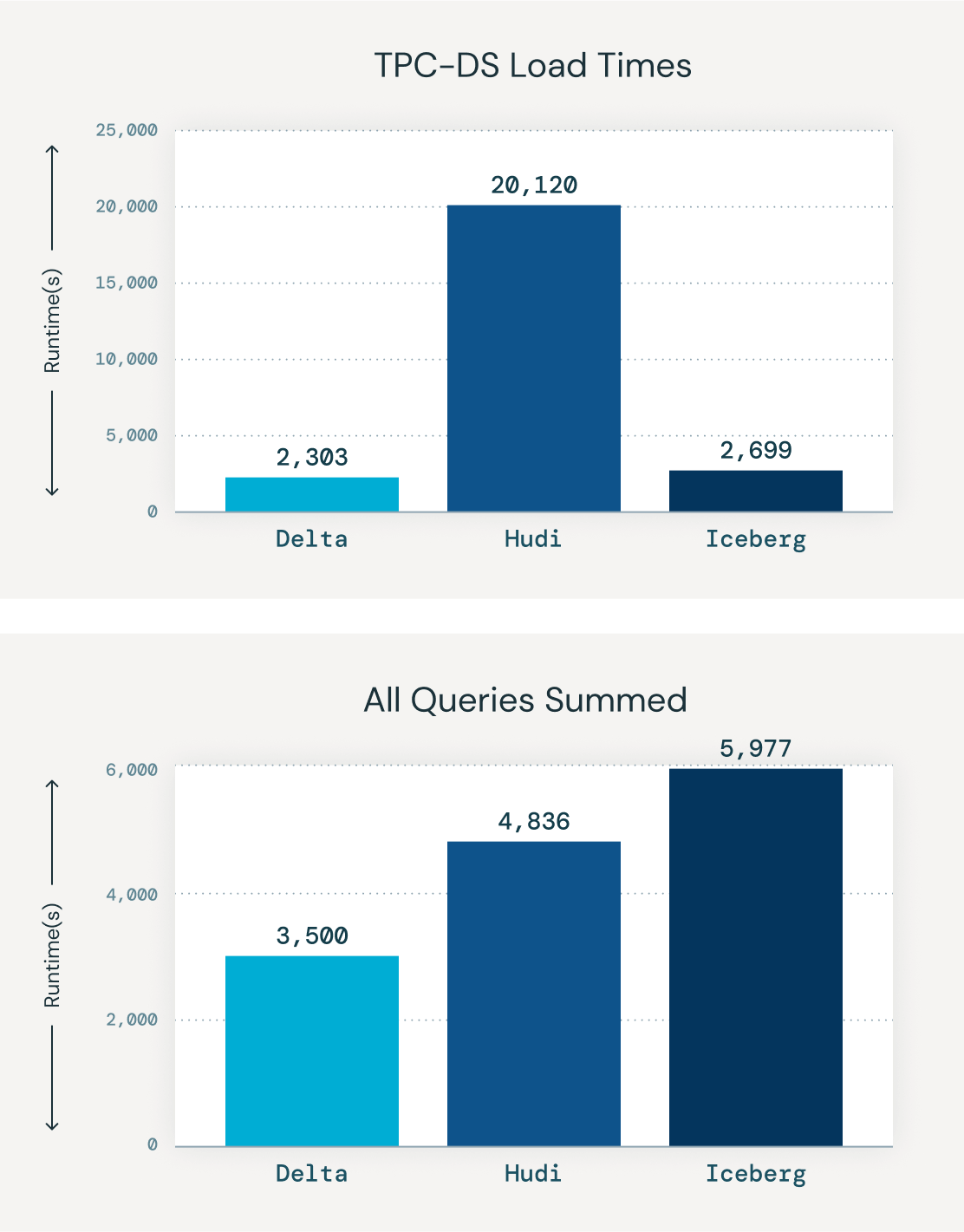
Fast and reliable performance
Delta Lake delivers massive scale and speed, with data loads and queries running up to 1.7x faster than with other storage formats. Used in production by over 10,000 customers, Delta Lake scales to process over 40 million events per second in a single pipeline. More than 5 exabytes/day are processed using Delta Lake.
When UniForm is enabled on Delta Lake tables, writing other format metadata does not compromise on query performance. UniForm tables deliver read performance on par with proprietary formats in their native engines.
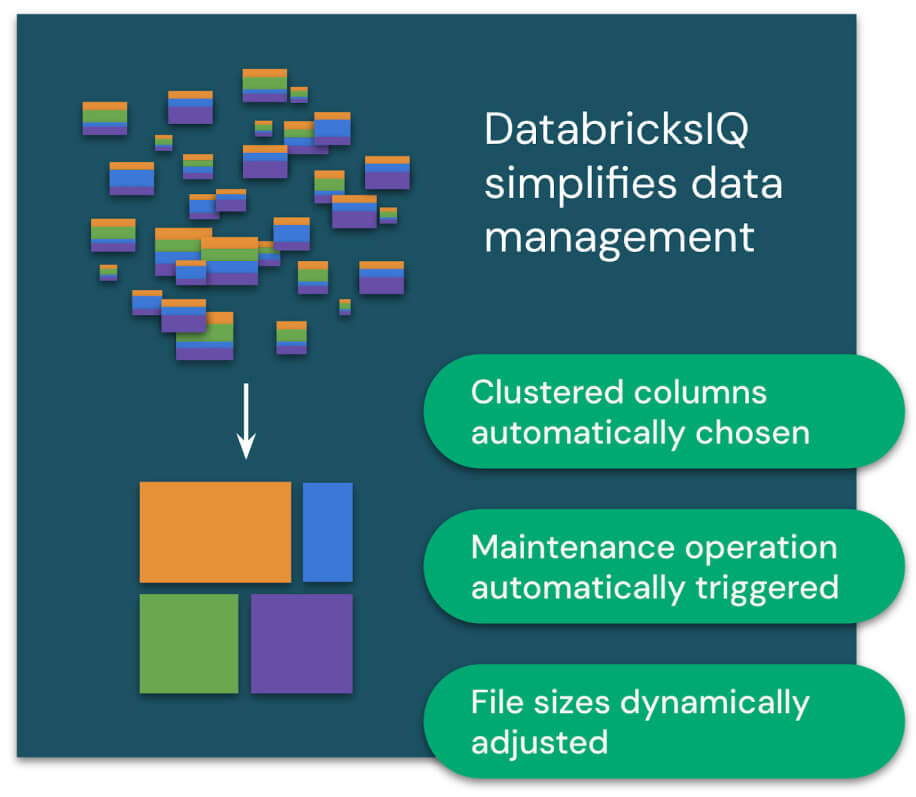
AI-driven for best price/performance
The Databricks Data Intelligence Platform optimizes your data based on your usage patterns. AI-driven performance enhancements — powered by DatabricksIQ, the Data Intelligence Engine for Databricks — automatically administer, configure and tune your data.
Liquid clustering delivers the performance of a well-tuned, well-partitioned table without the traditional headaches that come with partitioning, such as worrying about whether you can partition high-cardinality columns or expensive rewrites when changing partition columns. The result is lightning-fast, well-clustered tables with minimal configuration.
Predictive optimization automatically optimizes your data for the best performance and price. It learns from your data usage patterns, builds a plan for the right optimizations to perform, and then runs those optimizations on hyper-optimized serverless infrastructure.
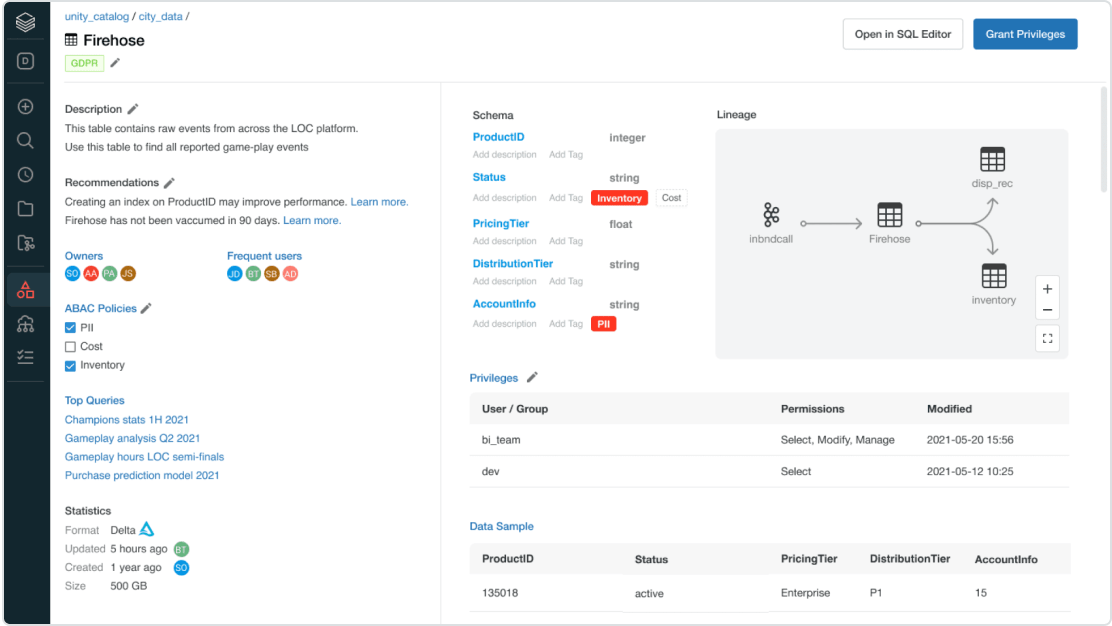
Security and governance at scale
Delta Lake reduces risk by enabling fine-grained access controls for data governance, functionality typically not possible with data lakes. You can quickly and accurately update data in your data lake to comply with regulations like GDPR and maintain better data governance through audit logging. These capabilities are natively integrated and enhanced on Databricks as part of the Unity Catalog, the first multicloud data catalog for the lakehouse.
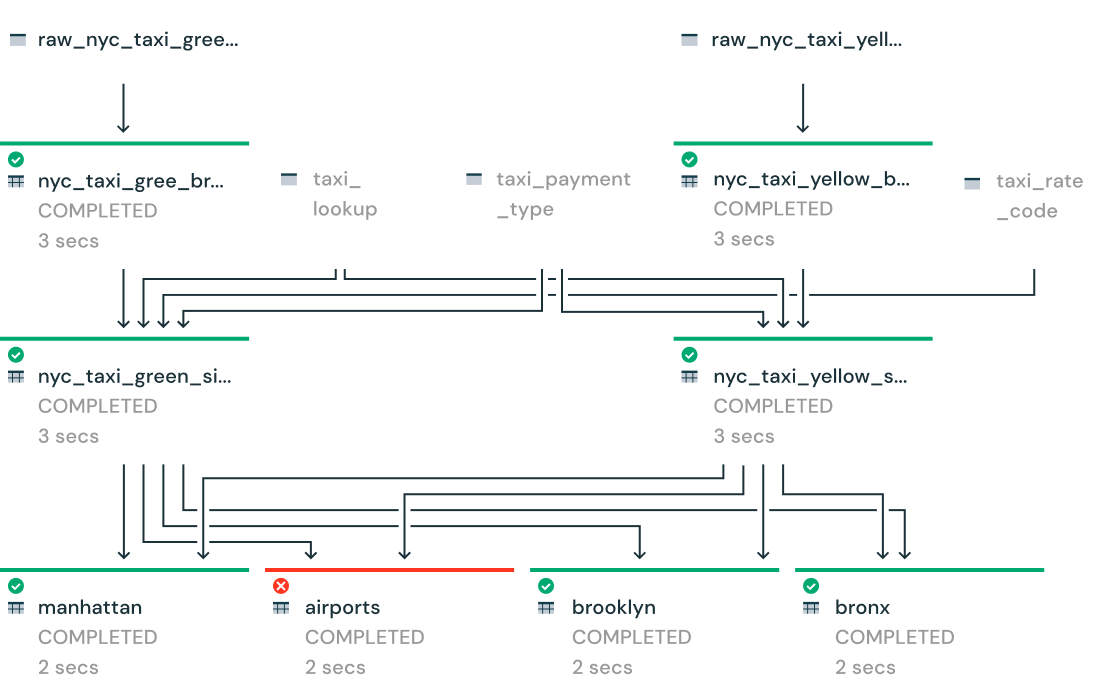
Automated and trusted data engineering
Simplify data engineering with Delta Live Tables — an easy way to build and manage data pipelines for fresh, high-quality data on Delta Lake. It helps data engineering teams by simplifying ETL development and management with declarative pipeline development, improved data reliability and cloud-scale production operations to help build the lakehouse foundation.
Use cases

BI on your data
Make new, real-time data instantly available for querying by data analysts for immediate insights on your business by running business intelligence workloads directly on your data lake. Delta Lake allows you to operate a multicloud lakehouse architecture that provides data warehousing performance at data lake economics for up to 6x better price/performance for SQL workloads than traditional cloud data warehouses.

Unify batch and streaming
Run both batch and streaming operations on one simplified architecture that avoids complex, redundant systems and operational challenges. In Delta Lake, a table is both a batch table and a streaming source and sink. Streaming data ingest, batch historic backfill and interactive queries all work out of the box and directly integrate with Spark Structured Streaming.

Meet regulatory needs
Delta Lake removes the malformed data ingestion challenges, difficulty deleting data for compliance, and issues modifying data for change data capture. With support for ACID transactions on your data lake, Delta Lake ensures that every operation either fully succeeds or fully aborts for later retries — without requiring new data pipelines to be created. Additionally, Delta Lake records all past transactions on your data lake, so it’s easy to access and use previous versions of your data to meet compliance standards like GDPR and CCPA reliably.
Discover more
Customers
“Databricks delivered the time to market as well as the analytics and operational uplift that we needed in order to be able to meet the new demands of the healthcare sector.”
– Peter James, Chief Architect, Healthdirect Australia
“By leveraging Databricks and Delta Lake, we have already been able to democratize data at scale, while lowering the cost of running production workloads by 60%, saving us millions of dollars.”
— Steve Pulec, Chief Technology Officer, YipitData
“Delta Lake provides ACID capabilities that simplify data pipeline operations to increase pipeline reliability and data consistency. At the same time, features like caching and auto-indexing enable efficient and performant access to the data.”
— Lara Minor, Senior Enterprise Data Manager, Columbia Sportswear
“Delta Lake has created a streamlined approach to the management of data pipelines. This has led to a decrease in operational costs while speeding up time-to-insight for downstream analytics and data science.”
— Parijat Dey, Assistant Vice President of Digital Transformation and Technology, Viacom18


